










DevStyle Portal - Programowanie i rozwój kariery w IT




Najnowsze

DevTalk Trio S03E02 – Czy Twój SaaS przetrwa erę LLM-ów?

Maciej Aniserowicz
DevTalk

DevTalk Trio S03E01 – Czy AI zastąpi programistów?
Maciej Aniserowicz
DevTalk

O Salesforce CRM ze Stanisławem Zaniem
Maciej Aniserowicz
Agentforce

O Archetypach i nowej roli w IT ze Sławomirem Sobótką
Maciej Aniserowicz
AI w IT
Backend

Architektura Ewolucyjna, DDD i Fitness Functions. Jak budować skalowalne systemy? (Q&A)
Team devstyle
ADR

Dlaczego prosty model User to za mało? Archetyp Party w praktyce (cz. 1)

Bartłomiej Słota
archetyp Party

Mikroserwisy: kiedy mają sens, a kiedy stają się pułapką?

Jakub Kubryński
architektura

Archetypy oprogramowania a wzorce projektowe GoF, jak różnią się od siebie i jak wspierają DDD
Bartłomiej Słota
Archetypy Oprogramowania
Frontend

Monorepo, mikrofrontendy, Lerna czy NX? Architektura zaczyna się od priorytetów biznesowych
Team devstyle
architektura frontendowa

Architektura frontendowa: czym jest a czym nie?

Tomasz Ducin
architektura
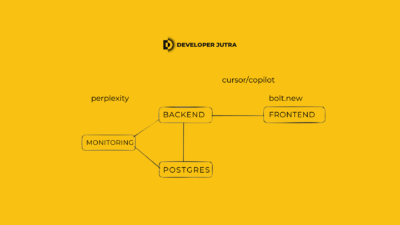
Fullstack z AI: Jak zbudować i wdrożyć aplikację z backendem, frontendem i monitoringiem w 2 godziny (Docker + Prometheus + React)
Team devstyle
AI

Czym właściwie jest Architektura (Frontendowa)?
Tomasz Ducin
architektura
Chmura

Apka działa, ale nie działa? Sprawdź, czy masz probe!

Piotr Zimoch
DevBites

Doświadczenia z BI w Azure w pigułce
Maciej Aniserowicz
azure

Azure Praktycznie z Mirkiem Burnejko i Damianem Mazurkiem (Chmurowisko)
Maciej Aniserowicz
amazon web services

Chcesz zostać Cloud Developerem? Oto 12 usług w Azure, które MUSISZ znać!
Maciej Aniserowicz
azure
Szkolenia devstyle










Na miękko

Czego AI nie rozumie? Podsumowanie LIVE o Archetypach Oprogramowania
Team devstyle
AI

Wdrażanie AI to nie nowy framework! Case Studies z live’a Architekt Jutra
Team devstyle
AI

Dostępność cyfrowa w praktyce, czyli technologia dla wszystkich
Team devstyle
accessibility

Pułapki promptowania w nauce z AI
Team devstyle
AI w nauce programowania













