












W poprzednim odcinku zarysowaliśmy ogólny cykl życia modelu językowego: trening i inferencję (wnioskowanie). Teraz przyszedł czas na ograniczenia, jakie z tego modelu wynikają – i jak sobie z nimi radzimy.
Wytrenowaliśmy model. Mamy go. Możemy go używać. Ale…
Świat idzie naprzód. Powstają nowe fakty, nowe wydarzenia, nowe odkrycia. A model – niekoniecznie je zna. Model jest niczym „frozen caveman” – zamrożony w czasie, w momencie zakończenia treningu. Jak bohaterowie „Seksmisji” – którzy są od-hibernowani w przyszłości i nie kumają, co się działo i co się dzieje. 😅
To w sumie całkiem dobra metafora też dla nas, programistów. Jak człowiek przestaje się aktualizować, to sam robi się takim „frozen devem” – zamrożonym w dawnych frameworkach i świętym przekonaniu, że wszystko już widział.
W Developerze Jutra kładziemy mocny nacisk właśnie na to, jak nie skończyć z mentalnym knowledge cutoffem.
Knowledge Cutoff
Z racji, że kiedyś trening dobiega końca (lub przynajmniej jego określona faza) – to ów stan wiedzy zostaje „zamrożony” (dopóki model nie jest zaprojektowany, aby się dalej uczył podczas inferencji – co jest relatywnie bardzo rzadkie).
Skądinąd, co znaczy GPT – Generative Pre-trained Transformer. W praktyce – w trakcie używania model niczego się nie uczy 🫠
W przypadku ludzi taki „cutoff” byłby trudny do zrealizowania – choć różne utwory Sci-Fi i nie tylko – potrafią niekiedy ciekawie zilustrować. Ciekawym nawiązaniem do kwestii „zarządzania pamięcią” człowieka jest odcinek White Bear z serii Black Mirror, którego spoilerować nie będę 😇.
‐ Skoro brakuje “aktualnej” “wiedzy”, to model byłby mało użyteczny?
‐ Dokładnie tak. I tu wchodzi RAG.
‐ A ten RAG to nie jest już aby podejście legacy?
‐ No nie, zupełnie nie. Bez RAGu – zazwyczaj – ani rusz.
RAG (Retrieval-Augmented Generation)
Retrieval-Augmented Generation, czyli technika, która pozwala “sięgnąć” do zewnętrznych źródeł wiedzy (np. baz danych, dokumentów, internetu). Montuje mnóstwo różnych źródeł danych..
‐ Modelowi?
‐ Nie. Agentowi (!!!)
‐ (cisza)… a to nie jest to samo? 🫣
I tu nam wjeżdża fundamentalna granica między agentem i modelem jako takim.
Meet the agent

“Agentem” możemy nazwać aplikację, która pod spodem “wykorzystuje” model językowy – ale dodaje do niego własną logikę biznesową i dodatkowe mechanizmy.
Agent NIE ROZUMIE requestu, który do niego przychodzi.
Sformułowania “agent przestrzega tego co jest w prompcie” to… 💩💩💩
Agent przekazuje prompt modelowi, potencjalnie uzupełniając go o kontekst, który może zawierać przeróżne informacje
- historię konwersacji
- preferencje użytkownika
- dane zaciągnięte z www
- system prompt (np. “na placu Tiananmen w 1989r. nic się nie działo, nie interesuj się, bo kociej mordy dostaniesz.”)
- a także przeróżną wiedzę, jaką agent zarządza (choć jej nie rozumie, nawet nie próbuje): może to być full-text-search, może być nawet zwyczajny SQL (zależy od potrzeb)
- a może to być baza “semantyczna” (wektorowa), która wymaga embeddingu (o tym w następnym odcinku) itp.
Agent zarządza kontekstem + komunikacją z modelem.
Prompt od usera, uzupełniony o kontekst, przekazuje do modelu…
Meet the model

Ten tutaj gość ma “małe okno” (kontekstowe 😛) które determinuje “ile tekstu można mu wepchnąć na raz”. Skojarzenia z karmieniem dzieci – zupełnie przypadkowe 😅
Okno jest mierzone w “tokenach” – o tym też w następnym odcinku. Jeśli prompt + kontekst przekroczą tę wartość – to model “zapomni” o tym, co było na początku. Dlatego zagadnienie zarządzania kontekstem jest tak mega ważne. Czasem się kontekst kompresuje, czasem się rozkazuje samemu modelowi “podsumować” to, co do tej pory agent z modelem “kminili” – bo przecież agent nie rozumie tekstu w języku naturalnym prawda?
Model zaś potrafi “interpretować” tekst w języku naturalnym (choć słowo “rozumieć” jest mega kontrowersyjne – ale to inny temat).
Sęk w tym, że typowy model nic nie pamięta z poprzednich interakcji 😂. Każda interakcja jest “od zera”. I to agent musi zadbać o to, aby model miał odpowiedni kontekst do pracy.
Model to taki matołek z którym się gada jak z nieprzytomnym. Za każdym razem.
Wprawdzie istnieją modele stanowe, ale większość istniejących modeli jest bezstanowa. Więc agent ma naprawdę sporo roboty.
Agent Loop
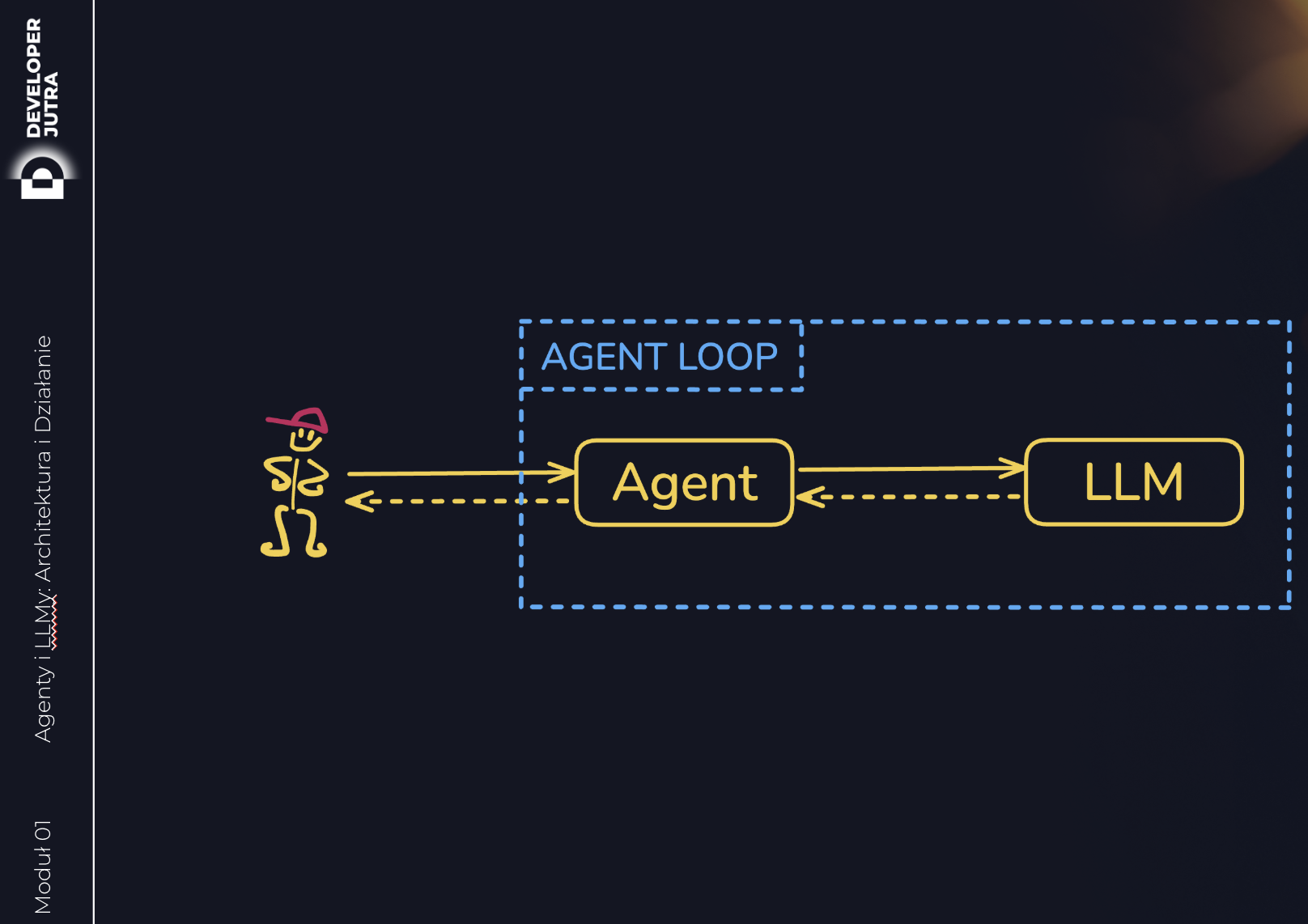
Kiedy user wysyła prompta, LLM odpytuje agenta, opcjonalnie dorzucając kontekst – tu wchodzi RAG. Dodatkowo, agent udostępnia “narzędzia” (nie tylko MCP), przekazując modelowi listę. I to model na jej podstawie decyduje, które narzędzie wybrać (o ile w ogóle). I jeśli takie wybierze, to przekazuje modelowi… JSON RPC 🙃 aby agent je wywołał.

Agent wywołuje narzędzie, dostaje wynik, i przekazuje go z powrotem do modelu – ale dodatkowo mówiąc całą historię od początku świata (“najpierw user chciał X, potem Ty mi napisałeś że mam wywołać Y, więc wracam z odpowiedzią Z i teraz wracamy z powrotem do X”). I model na tej podstawie:
- albo każe wywołać kolejne narzędzie
- albo generuje finalną odpowiedź
Krótka piłka – agent albo rozpoznaje JSONa (tylko albo aż tyle) – i jest to po prostu “function call” / “tool use” (niespójne nazewnictwo wśród vendorów – skąd my to znamy…). A jeśli nie JSON – to siup, odpowiedź jedzie do usera.
Zarządzanie Kontekstem
Jest tutaj jednak jeden “haczyk”.
Ty, drogi/a programist(k)o, im więcej plików wciskasz do kontekstu swojego IDE, im więcej ogromnych reguł zbudujesz i ustawisz na “always”, im więcej niepotrzebnie będziesz zlecał agentowi, im będziesz prowadził dłuższe wątki (…) tym więcej tokenów przepalisz.
Bo na wejściu do modelu – i na wejściu to kesza long-term memory (tam gdzie agent przechowuje kontekst – cokolwiek by to nie było) – jest taki “taksometr”, swoista “kasa fiskalna”, która bije… i nalicza te tokeny…
Im więcej paździerza niepotrzebnie pchasz do kontekstu – tym większy będziesz mieć rachunek – i tym większe rozczarowanie.
Omawiamy ten temat oczywiście w Developerze Jutra 😎
Tymczasem w następnym odcinkach przyjrzymy się, w jaki sposób modele “rozumieją” język naturalny – czyli jak w ich “tensorach” (macierzach i wektorach) “powstaje” semantyka i interpretacja.




