












Czym jest residuality i jak pomaga budować systemy, które przetrwają nieprzewidywalne sytuacje? W tym artykule poznasz podstawy tej koncepcji, proste narzędzia i przykłady.
Czym jest residuality?
Gdy mówimy o architekturze systemów, zwykle myślimy o komponentach, mikroserwisach, diagramach, logice domenowej. Projektujemy funkcjonalności, integracje i happy pathy. Ale co, jeśli coś pójdzie nie tak? Blackout? Zmiana prawa? Odejście kluczowej osoby? Albo AI, które 24/7 crawluje nasze API?
Barry O’Reilly proponuje nowe podejście: residual architecture. Nie projektujemy od funkcji do odporności, tylko odwrotnie – od stresorów do pozostałości (residue), które przetrwają.
- Stresor to każde zdarzenie, które wystawia system na próbę: techniczne, organizacyjne, polityczne, absurdalne lub realistyczne.
- Residue to to, co przetrwa, gdy stresor uderzy. Może to być komponent, konfiguracja, proces, zachowanie użytkownika – cokolwiek, co sprawi, że system nadal będzie działać, choćby w ograniczonej formie.
O’Reilly nazywa to residuality, ale można myśleć o tym jako o świadomym projektowaniu systemu, który zamiast być idealnie „poprawny”, jest odporny i potrafi przetrwać w nieprzewidzianych warunkach.
Dlaczego to podejście ma sens?
Resztkowość (residuality) to koncepcja zakorzeniona w complexity science. Zamiast przewidywać każdy możliwy scenariusz awarii, uczymy się projektować systemy, które będą odporne – nawet jeśli nie wiemy, co dokładnie się wydarzy.
O’Reilly pokazuje, że tradycyjna architektura software’owa to próba wsadzenia uporządkowanego systemu w nieuporządkowany świat (biznes, rynek, prawo, społeczeństwo). Nasze plany rozbijają się o rzeczywistość. Residuality podsuwa inne pytania:
- Co się stanie, gdy X się wydarzy?
- Co zostanie z naszego systemu?
- Czy z tej resztki da się kontynuować działanie?
Zamiast próbować oceniać prawdopodobieństwo każdego możliwego zdarzenia, co w praktyce często oznacza, że decyzje podejmują osoby o największym wpływie lub najgłośniejszym głosie – stosujemy random simulation. Losowo wymyślamy stresory i analizujemy, co w systemie przetrwa. To podejście pozwala dostrzec wzorce odporności, a często jedno residue wystarcza, by poradzić sobie z wieloma różnymi zagrożeniami.
Residue w praktyce
Stacje ładowania electric vehicles (EV)
Jednym z głównych przykładów używanych przez O’Reilly’ego jest system do ładowania samochodów elektrycznych:
- Stresor: klient nie może się zalogować
- Residue: system rozpoznaje tablicę rejestracyjną (ALPR) i pozwala ładować
Inny stresor: spalinówka blokuje ładowarkę (tzw. “icing”). Ten sam komponent – ALPR – plus faktura za blokadę pozwalają systemowi przetrwać również ten przypadek.
O’Reilly pokazuje, że residue są często wielokrotnego użytku: jedno rozwiązanie rozwiązuje kilka problemów.
Case z firmy Arkency
Zanim poznaliśmy teorię residuality, wdrożyliśmy rozwiązanie, które dziś dałoby się zinterpretować jako residue.
Jeden z klientów poprosił o dodanie drugiej bramki płatniczej, jako zabezpieczenia na wypadek awarii. Rozwiązanie (szybkie przełączanie z panelu admina) okazało się przydatne także… w negocjacjach. Gdy dostawca bramki zapowiedział podwyżkę, właściciel firmy przełączył się na żywo na inną bramkę i podwyżka została wycofana. Residue zaprojektowane pod stresor techniczny zadziałało też w przypadku stresora biznesowego.
Jak projektować residual architecture?
Nie musisz przewidzieć wszystkich scenariuszy awarii ani próbować nadać im prawdopodobieństw. Wystarczy, że uchwycisz klasy stresorów, czyli czynniki, które mogą uderzyć w Twój system, i sprawdzisz, które komponenty są na nie podatne. W praktyce można to zrobić w dwóch krokach.
1. Lista stresorów i residuów
Najpierw tworzysz listę stresorów (np. blackout, zmiana prawa, masowe działanie AI-crawlerów) i opisujesz, jakie residua – zmiany w architekturze – pozwoliłyby systemowi przetrwać każdy z nich.
Przykład:
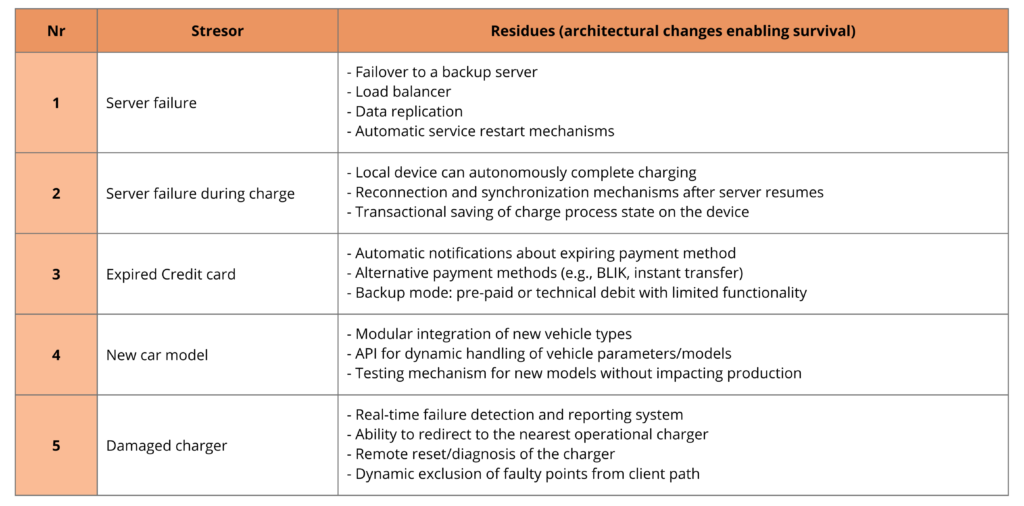
Dzięki temu:
• masz jasny obraz zagrożeń i wstępnych sposobów radzenia sobie z nimi,
• unikasz skupiania się wyłącznie na scenariuszach uznanych za najbardziej prawdopodobne, które często pomijają istotne, ale rzadko rozważane ryzyka.
2. Macierz incydentów (incidence matrix)
Kolejny krok to narzędzie, które Barry O’Reilly opisuje jako incidence matrix.
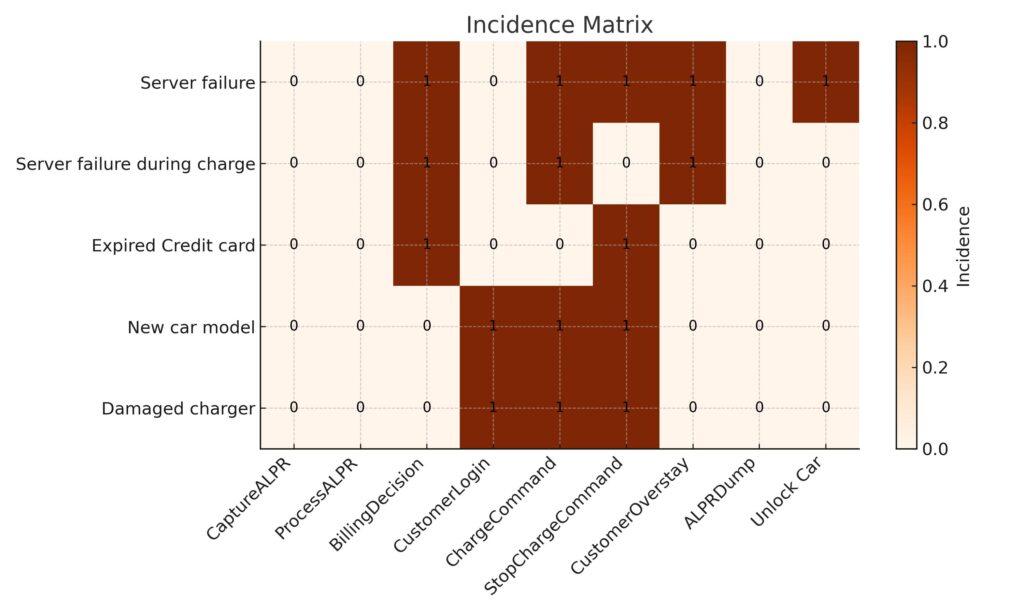
Źródło: An Introduction to Residuality Theory – Barry O’Reilly – NDC London 2024
Jak czytać macierz incydentów?
Macierz incydentów (incidence matrix) to narzędzie, które Barry O’Reilly proponuje do analizy odporności systemu na stresory. Wiersze macierzy przedstawiają stresory – zdarzenia, które mogą wystawić system na próbę. W tym przykładzie są to m.in. Server failure, Server failure during charge, Expired credit card, New car model, Damaged charger.
Kolumny odpowiadają komponentom systemu, zarówno technicznym (np. ChargeCommand, StopChargeCommand) jak i biznesowym (np. BillingDecision, CustomerLogin).
Wartości w komórkach pokazują wpływ stresora na komponent:
-
1 (ciemne pole) – stresor wpływa na dany komponent,
-
0 (jasne pole) – brak wpływu.
Analiza wzorców jedynek pozwala ujawnić niefunkcjonalny coupling, czyli sytuacje, w których komponenty mogą przestać działać jednocześnie pod wpływem tego samego stresora, mimo że w logice biznesowej nie są ze sobą powiązane.
Przykłady z macierzy:
-
Server failure wpływa równocześnie na BillingDecision, ChargeCommand i Unlock Car. Oznacza to, że awaria serwera może jednocześnie sparaliżować proces płatności, sterowanie ładowaniem i odblokowanie pojazdu.
-
Damaged charger dotyka ChargeCommand i StopChargeCommand, co pokazuje, że jedna usterka sprzętowa zakłóca zarówno rozpoczęcie, jak i zakończenie procesu ładowania.
Dzięki macierzy można:
-
wskazać punkty wspólnego ryzyka (single points of failure),
-
zidentyfikować komponenty wymagające rozsprzęgnięcia lub redundancji,
-
dostrzec elementy o identycznym wzorcu reakcji i rozważyć ich scalenie lub wspólne zabezpieczenie.
Wykorzystanie incidence matrix na innym przykładzie
Jeśli chcesz zobaczyć, jak na innym przykładzie wykorzystać takie narzędzie, warto zajrzeć do artykułu Oskara Dudycza „Residuality Theory: A Rebellious Take on Building Systems That Actually Survive”. Oskar pokazuje w nim dwie wersje macierzy incydentów – przed i po wprowadzeniu zmian projektowych – co świetnie obrazuje, jak konkretne decyzje architektoniczne i procesowe wpływają na odporność systemu.
Dla kogo jest residuality?
Dla architektów systemów – jako metoda do projektowania odporności, niezależnie od tego, czy pracują nad mikroserwisami czy monolitem. Residuality pozwala analizować zależności, które nie wynikają z logiki domenowej, ale z warunków zewnętrznych.
Dla programistów – by zobaczyć ryzyka, których nie widać w kodzie. Niefunkcjonalny coupling może ujawniać się dopiero w sytuacjach kryzysowych – residuality pomaga go rozpoznać wcześniej.
Dla zespołów – jako wspólny język do rozmów o odporności, stresorach i kompromisach. Pomaga podejmować decyzje nie tylko o tym, co wdrażamy, ale też o tym, co musi przetrwać, gdy coś się posypie.
I co z tego wynika?
Nawet jeśli nie wdrożysz całej metodyki, samo myślenie o stresorach i residuach poszerzy Ci perspektywę. Możesz znaleźć uniwersalne rozwiązania, które zaadresują wiele problemów naraz, zanim się wydarzą.
Jak residuality uzupełnia DDD i Event Sourcing?
Residuality nie konkuruje z podejściami takimi jak Domain-Driven Design czy Event Sourcing. Uzupełnia je, dodając nową perspektywę: co zostaje, gdy coś się psuje.
DDD skupia się na poprawnym modelu domenowym
Ale nie zawsze odpowiada na pytania:
- Co jeśli klient nie może zapłacić?
- Co jeśli endpoint przeciąży AI-crawler?
- Co zostaje z modelu, gdy padnie serwer lub odejdzie zespół?
➡ Residuality pozwala ocenić, czy nasz model przetrwa stresor, a jeśli nie – co warto dodać, by go wzmocnić.
Event Sourcing może prowadzić do ukrytych zależności, które nie są widoczne na poziomie logiki, ale ujawniają się w kryzysie.
Wyobraźmy sobie kilka komponentów w systemie – np. zamówienia, fakturowanie i pricing. Na diagramie wyglądają niezależnie, każdy ma swój model i działa osobno. Ale wszystkie korzystają z tego samego wzorca technicznego – agregatu z Event Sourcingiem.
W sytuacji dużego obciążenia, np. gdy klient składa zamówienie na 5000 pozycji, okazuje się, że agregaty nie nadążają z przetwarzaniem. I nagle te niezależne komponenty padają razem, mimo że nie są ze sobą połączone funkcjonalnie.
➡ Podejście residuality pomaga zobaczyć ten ukryty problem i zadać pytanie: czy na pewno wszystkie komponenty muszą być oparte na tym samym wzorcu? Czy da się rozdzielić ich zachowanie tak, by nie zawodziły jednocześnie?
Wniosek:
To nie konkurencja dla DDD, event sourcingu czy monolitu. To uzupełnienie warsztatu: sposób myślenia, który porządkuje intuicje i pozwala je wyrazić w sposób systemowy. Pomaga zespołom zrozumieć, które komponenty są kluczowe w sytuacjach kryzysowych, a które można poświęcić. Wnosi do projektowania architektury brakującą warstwę: odporność na nieznane stresory, które mogą uderzyć w system niezależnie od tego, jak poprawnie działa na co dzień.
Na zakończenie
Residuality to podejście, które pomaga świadomie projektować systemy odporne na zmienność i zakłócenia. Ostatnie lata (pandemia, wojna, blackouty, rozwój AI) pokazały, że o przetrwaniu systemu coraz częściej decydują czynniki spoza kodu.
Doświadczeni architekci często podejmują trafne decyzje projektowe na podstawie intuicji. Trudniej jednak wyjaśnić, dlaczego konkretna architektura potrafi przetrwać kryzys. Residuality porządkuje to myślenie i nadaje mu strukturę. Oferuje narzędzia, które pomagają analizować stresory, rozpoznawać zależności i projektować komponenty utrzymujące podstawową funkcjonalność nawet w przypadku awarii. Nie chodzi o doskonałość. Liczy się to, by system zachował ciągłość działania tam, gdzie jest to najważniejsze.
Więcej na temat residuality znajdziesz tutaj:
📘 Barry O’Reilly – Residuality Theory
🎥 Prelekcja Barry’ego O’Reilly z NDC London 2024






