












W poprzednich odcinkach przyjrzeliśmy się ogólnemu cyklowi życia modelu językowego (trenowanie i inferencja) oraz temu, jak modele “rozumieją” (a raczej: przetwarzają) język naturalny w oparciu o semantykę, atencję i tensory. Teraz kontynuujemy, zagłębiając się w konsekwencje takich a nie innych decyzji architektonicznych 🥩.
Modele halucynują 😵💫 każdy/a z nas się prawd. z tym zetknął/ęła.
Z czego się to bierze?
Next token generation
Przypomnijmy sobie pełen cykl inferencji (wnioskowania):
- User wysyła prompta (tekst)
- Prompt jest tokenizowany, embeddowany i pozycjonowany (zamieniany na wektory liczb)
- Wektory są przetwarzane przez model w blokach transformerowych (atencja, FFN – operacje na tensorach)
- Model generuje wektory wyjściowe

(tu jesteśmy)
Można by powiedzieć, że we wszystkich poprzednich krokach, model budował swoiste “rozumienie” (macierze, wiadomo), które zawiera zarówno jego “wiedzę” (tę która podlega knowledge cutoff), w swoistym przecięciu razem z promptem i kontekstem, jaki model dostał z zewnątrz.
‐ I teraz model na podstawie macierzy ma generować “wektory odpowiedzi”? Brzmi to jak masło maślane.
‐ No, technicznie, tak. Powiem więcej: tokeny wyjściowe są “statystycznie LOSOWANE” (!!!). I to jest właśnie klucz do zrozumienia, dlaczego modele halucynują.
‐ Losowane? Co Ty gadasz? Przecież model jest wytrenowany, on wie co ma odpowiedzieć!
‐ Tak, jeszcze mi powiedz, że zbudują armię agentów, które spowodują masowe bezrobocie wśród programistów… 🙃
De-embedding
Nie ma takiego słowa 🙃 (I made it up)… ale zasadniczo – z wygenerowanego wektora na outpucie zrobimy z powrotem “dekodowanie” tego wektora na token (tekst).
I będziemy to robili sekwencyjnie – wskutek czego powstanie ciąg tokenów (tekst). Który będzie miał składniowy i logiczny sens (choć mogą wystąpić semantyczne “halucynacje”) pod warunkiem, że trening modelu był “jakościowy”.
Łatwo powiedzieć – tylko jak te wektory są losowane… tu wchodzi probabilistyka – lub jak kto woli, statystyka (ostatecznie, na jedno wychodzi).
Softmax, Sampling, Temperatura
Nie chcę tu zamęczać matematyką (choć mógłbym 🔥😈) – ale w dużym uproszczeniu:
- powstaje nam słownik możliwych tokenów wyjściowych z odpowiednimi wagami (prawdopodobieństwami)
- te prawdopodobieństwa są “normalizowane” (softmax) – aby ich suma dawała 1 (100%)
- na podstawie tych prawdopodobieństw – losujemy token – i tu wchodzą techniki samplingu
- wektor (potem token) jest losowany, powtórz iterację od pkt 1 dla następnego tokenu while NIEPRAWDA_ŻE wylosowano token końcowy “EOS” (end-of-sequence) 🫠
Cały młyn transformerowy robi tyle, że generuje nam ten słownik z prawdopodobieństwami. Można by rzec, że całe wcześniejsze mielenie macierzy jest tylko po to, aby obliczyć te prawdopodobieństwa tokenów wyjściowych.
Czyli nie że LLMy w większości “uprawiają” probabilistykę – bo w większości to uprawiają algebrę liniową – ale ostatecznym celem jest właśnie probabilistyka, która skutkuje już bezpośrednio outputem dla usera.
I teraz – w tym miejscu – mamy kilka “dźwigni”, które możemy ustawić, aby wpłynąć na charakter generowanych odpowiedzi…
Temperatura
Hackujemy nią softmax. Możemy sprawić, że rozkład prawdopodobieństw będzie:
- bardziej “płaski” (więcej tokenów będzie miało zbliżone prawdopodobieństwo) lub
- bardziej “spiczasty” (kilka tokenów będzie miało bardzo wysokie prawdopodobieństwo, a reszta bardzo niskie).
Im wyższa temperatura, tym bardziej “płaski” rozkład.
Niech przemówią slajdy z Developera Jutra 😉
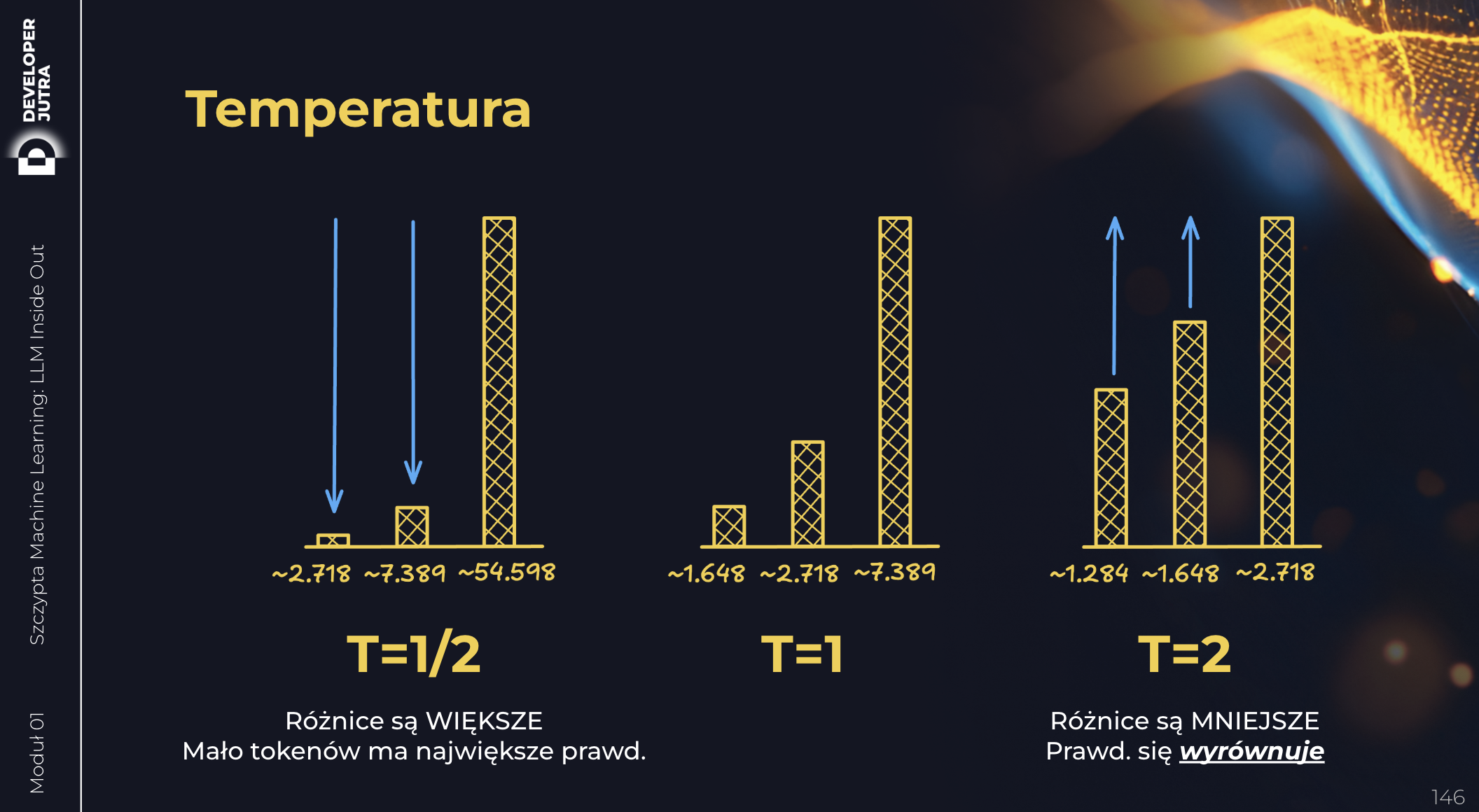
Zasadniczo, temperaturę ustawia się w zakresie od 0.0 do 1.0. Dlaczego? Bo przy temperaturze > 1 rozkład prawdopodobieństwa zaczyna się “wypłaszczać” (co w przypadku pandemii było pożądane, ale w przypadku LLMów zupełnie nie 😅) – bo to oznaczałoby że token sensowny i totalnie od czapy “zbliżają się” pod kątem prawdopodobieństwa.
‐ A po co mi to?
‐ Mordeczko, możesz przecież ustawić temperaturę jako parametr, łącząc się z modelem przez API!
‐ No tak, ale po co?
‐ No właśnie po to, aby wpłynąć na charakter generowanych odpowiedzi!
‐ Czyli jak?
‐ Nooo… przy niskiej temperaturze (np. 0.2) model będzie generował bardziej przewidywalne, spójne i “bezpieczne” odpowiedzi. Przy wysokiej (np. 0.8) – bardziej kreatywne, zróżnicowane, ale też ryzykowne (potencjalnie więcej halucynacji). Przy niskiej temperaturze jest nudno, przy wysokiej jest balanga ze wszystkimi jej konsekwencjami
‐ Aha, ale ja nie łączę się z modelem przez API…
‐ To nic – wiele aplikacji czatowych pozwala ręcznie ustawić temperaturę z GUIacza 😉
‐ 🥹
Sampling
Są jeszcze inne mechaniki “hackowania” sposobu losowania tokenów. Np. top-k sampling lub top-p (nucleus) sampling.
Halucynacje
Te również można ustawiać w niektórych GUIaczach, a już tym bardziej w API.
‐ No ale co z tymi halucynacjami?
‐ No tak – najlepsze zostawiliśmy na koniec 😉
‐ No więc?
‐ Halucynacje biorą się stąd, że model ma możliwość losowania tokenów, które są statystycznie mniej prawdopodobne – lub są spoza zakresu “wiedzy” modelu. A im mniej prawdopodobne tokeny, tym większa szansa, że powstanie coś “od czapy”.
‐ To czemu ma losować mniej prawdopodobne tokeny?
‐ Ustaw odpowiednią temperaturę…
‐ Ahaaaa…
Sęk w tym, że model generuje “następny token” w oparciu nie tylko o “zbudowaną reprezentację semantyczną” (na podstawie prompta, kontekstu i swojej “wiedzy”), ale też o to, co już do tej pory wygenerował (dotychczasowe tokeny wyjściowe).
I teraz – prompt engineering is a thing – przynajmniej do pewnego stopnia 😉. Jeśli nakażesz modelowi na początku zrobić plan działania – i to trafi w początkowych tokenach – to potem losując kolejne tokeny – na ich podstawie – znacząco zwiększamy prawdopodobieństwo, że reszta odpowiedzi będzie “aligned” do planu, który właśnie co wygenerował.
‐ Brzmi nieźle…
‐ Nooo 😅, ale to nie rozwiązuje problemu halucynacji do końca… Nie da się go wykluczyć – można go tylko minimalizować.
A dodatkowo – powyższa technika – przy odpowiednio dużych modelach – nie wynika już ANI z prompta, ANI z agenta/kontekstu – tylko z samych trzewii modelu.
Przy odpowiedniej skali (np. rozmiarze tensorów i liczbie warstw + oczywiście jakości treningu i jego wielu fazach) – model nabywa umiejętności “emergentnych”, które marketing szumnie nazwał “reasoning” (np. rodzina modeli o1, o3, o4, czy także gemini 2.5, opusy itp – zasadniczo – te nowe i te drogie 😅).
‐ Emergentne? 🤔
‐ Tak, czyli takie, które “pojawiają się” przy odpowiedniej skali modelu – ale nie wynikające z zaplanowania ich explicite. Chocapic – czary z mleka.
‐ Fascynujące to wszystko…
‐ Tak jest – i dlatego zachęcam do dołączenia do Developera Jutra




