












W poprzednim odcinku zarysowaliśmy ogólny cykl życia modelu językowego: trening i inferencję (wnioskowanie). Teraz przyszedł czas na wejście w semantykę, abstrakcje i to, jak modele “rozumieją” (a raczej: przetwarzają) język naturalny.
TL;DR: Semantyka i sposób jej internalizacji w modelach językowych to klucz do zrozumienia ich możliwości (!) i ograniczeń (!!!). Przeróżne techniki (promptowania, zarządzania kontekstem) i mechanizmy (atencji, kwantyzacji, halucynacji i masa innych) mają swoje uzasadnienie w matematycznej naturze LLMów i tego, jak budują “rozumienie” semantyczne.
Semantyka
Semantyka jako taka – to nauka o znaczeniu słów i zdań w języku naturalnym…
‐ OMG, definicje ble… 🤢
No to spójrzmy na przykład. Weźmy na warsztat słowo “jabłko” 😃

Możemy rozpatrywać je przez bardzo wiele różnych perspektyw:
- jako słowo – jako ciąg znaków (literek), pod kątem gramatycznym fleksji języka polskiego (lub innego)
- jako żywność – coś co się je
- jako składnik przepisów kulinarnych, np. składnik do ciasta
- jako element rozgrywek politycznych, np. między Polską i Rosją (jabłka z importu)
- jako towar, który się transportuje, sprzedaje, kupuje
- jako symbol (np. jabłko Newtona)
- jako marka (np. Apple)
- jako element sztuki (np. “Czerwone jabłka” Cezanne’a)
- jako element religijny (np. jabłko Adama i Ewy) itp. tu mogę się zatrzymać. Kumasz o co chodzi :)
I teraz – kiedy mówisz/piszesz “jabłko” – to o co Ci konkretnie chodzi? Na jakiej płaszczyźnie myślisz o słowie “jabłko”? Z czym ją kleisz? Jakie ma powiązania? Jakie skojarzenia?
W zależności od kontekstu, może Ci chodzić o zupełnie inne rzeczy, prawda?
My, ludzie, aby się efektywnie komunikować, stworzyliśmy sobie pewne meta-perspektywy, swoiste klucze interpretacyjne, które pozwalają nam patrzeć na pewne byty ze świata rzeczywistego (lub pewne abstrakty) w podobny sposób. Abyśmy szybciej mogli się zrozumieć – i zrobić coś, co zrobić potrzebujemy.
‐ Czy modele językowe również mają takie meta perspektywy? 🤔
‐ I tak i nie 🙃. Bo to zależy jak zdefiniujemy taką meta-perspektywę.
Człowiek może przetwarzać informacje z różnych perspektyw, naturalnie balansując między wieloma jednocześnie. Kilka przykładów: gramatyczny, semantyczny, pragmatyczny, kulturowy, historyczny, emocjonalny, egzystencjalny. itp.
Z kolei Model językowy – ten umie w matematykę, nie w filozofię i/lub humanizm. Jego podstawowym “budulcem” są tensory (macierze i wektory) i operacje na nich (głównie, choć nie tylko: mnożenie i dodawanie). I takie “meta-perspektywy” dla modelu muszą się niejako “zmieścić” w tych tensorach – bo innego capacity (zdolności do przechowywania swojej “wiedzy”) model nie ma.

Teoretycznie model mógłby w jednej (konkretnej) macierzy umieścić np. wagi dla “meta-perspektywy” biznesowej – i wtedy przepuszczać przez nią “słowa” (nie słowa per se, nie tokeny, ale wektory – ale o tym później) i “oceniać” je pod kątem biznesowym. A np. inną macierz pod kątem etycznym. I tak dalej. I z tymi “ocenami” iść wgłąb matematyki LLMowej, mając na celu ostateczne wygenerowanie wartościowej i celnej odpowiedzi.
Czy taki scenariusz jest możliwy? Teoretycznie – tak. Praktycznie – niekoniecznie – “to zależy” głównie od tego, jak przebiega trening modelu.
No ale pewnie domyślasz się, że to jest zbyt uproszczone wyobrażenie 😉 Trenując model, dysponujemy pewną jego przepustowością – szeroko ujmując, określa to całkowita liczba parametrów modelu, do niedawna idąca w miliony, obecnie w miliardy, a “domniemany” rozmiar już i to przekracza (jbc, uwaga: w polskim milion, miliard, bilion, biliard, … jest delikatnie inny niż w ang. “million, billion, trillion, quadrillion, …”).
W dużym uproszczeniu, ale wystarczającym do złapania idei – model (wskutek treningu) “buduje sobie” swoje klucze interpretacyjne, które NIE SĄ 1:1 analogiczne do naszych (ludzkich), gdzie istnieje np. meta-perspektywa biznesowa lub etyczna.
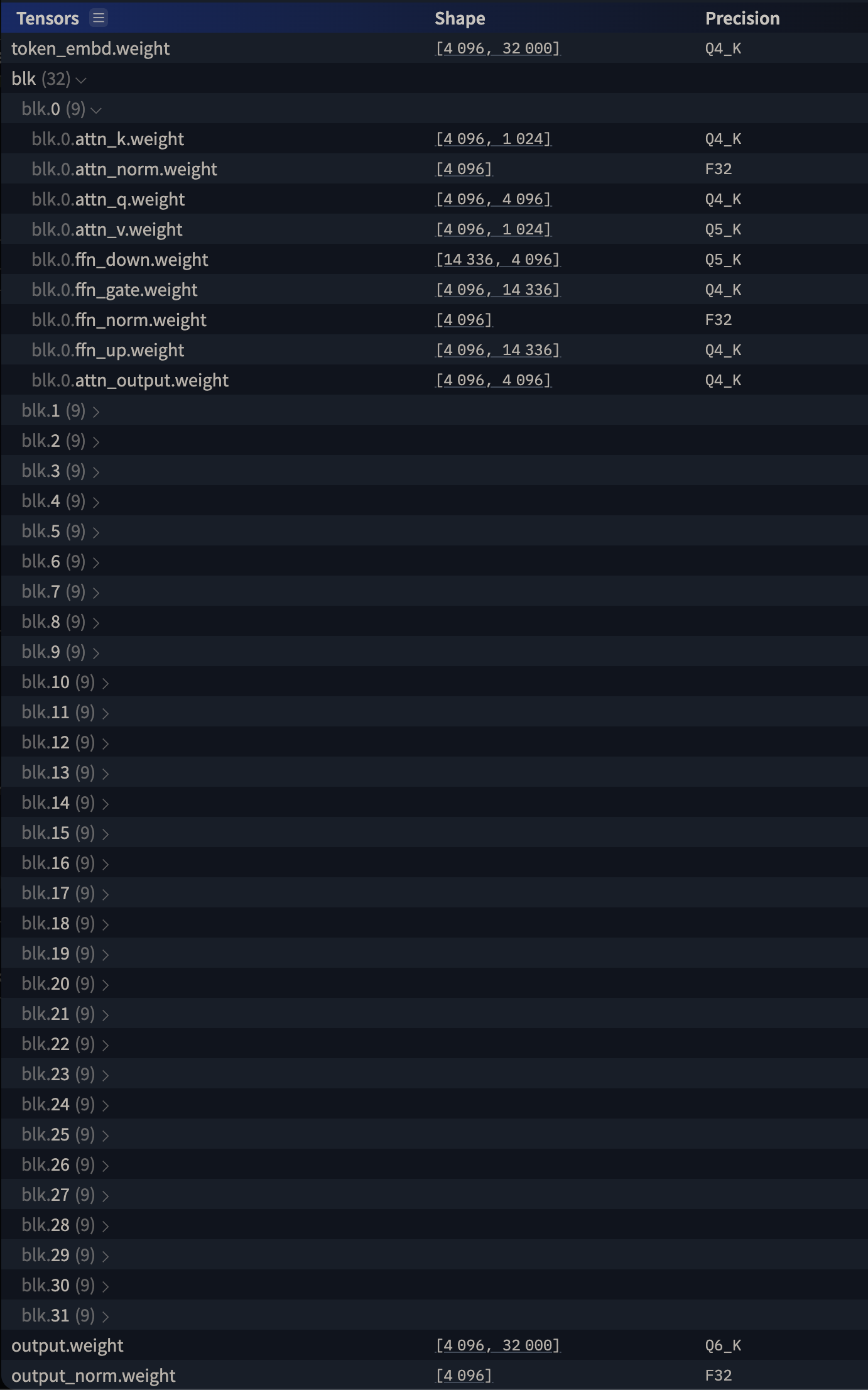
Powyżej widzimy wewnętrzną strukturę “wiedzy” modelu Bielik w konkretnej wersji. O architekturze wewnętrznej LLMów mówię bardzo dużo w Developerze Jutra – ale w dużym skrócie – ta “wiedza” to fizycznie (między innymi) wspomniane wcześniej tensory (macierze, wektory itp) która w architekturze Transformers jest “upakowana” warstwowo. I każda warstwa składa się najpierw z atencji (w różnych smakach, kolorach i odcieniach), a potem z feed-forward neural networks (FFN), która – przynajmniej wzorcowo – jest typową sztuczną siecią neuronową (ANN).
W Developerze Jutra schodzimy też, w jednej lekcji, w głąb tego co (niemalże każda) warstwa w całym modelu oznacza, i jaką rolę pełni.
Kiedy model “wnioskuje”, przelicza dane wejściowe (prompt) przez kolejne warstwy, każda z nich “modyfikuje” (przetwarza) te dane w oparciu o swoje tensory (macierze i wektory). I tak dalej, i tak dalej, aż do samego końca. Na końcu jest generowanie odpowiedzi oparte o statystykę (softmax, temperatura, sampling – o tym innym razem).
Tak czy siak – my w naszym mózgu mamy neurony, synapsy i przeróżne inne konstrukty w mózgu. Zaś klasyczny model (oparty o Transformers) ma (między innymi, bo nie tylko) warstwy: atencję i FFN.
I tu dochodzimy do absolutnie fenomenalnego cytatu:
All models are wrong, but some are useful.
I doskonale (wg mnie) tę myśl ilustruje Jaskinia Platona – gdzie ludzie widzą jedynie cienie rzeczywistości, a nie samą rzeczywistość:

Jeśli mówimy o “meta-perspektywach” myślenia ludzkiego (biznes, etyka, etc), to też pytanie: na jakim poziomie o tym mówimy? Fizycznie, ludzki mózg składa się m.in. z neuronów i synaps.
I tak jak mózg ma pewną przepustowość (którą, znowu, w ograniczonym ujęciu możemy “zrównać” do liczby neuronów idącą przeciętnie w 80-100 mld w jednym ludzkim mózgu), tak model też ma przepustowość określoną liczbą parametrów. Ale zarówno mózg, jak i LLM, to znacznie więcej, niż przepustowość/struktura. To też “emergentne” zdolności, które pojawiają się wraz z pójściem w odpowiednio dużą skalę.
Abstrakcje
Wchodząc na nieco wyższy poziom – zamiast o tensorach/neuronach – możemy mówić o “myśleniu”, “emocjach”, “kulturze”, “etyce” itp. – a to już zupełnie inny poziom abstrakcji.

W jaki zatem sposób w ludzkim mózgu słowo “jabłko” może – w zależności od kontekstu – prowadzić do tak różnych interpretacji?
Dysponujemy technologiami, które pozwalają badać aktywność mózgu (np. EEG, MEG, fMRI, PET itp) ale wciąż sporo nam brakuje od pełnego zrozumienia, jak to działa.
Fascynujące jest to, że im głębiej “wchodzimy” w LLMy (jednocześnie ucząc się o ich działaniu, jak i nabywając hands-on experience), tym zauważamy więcej analogii między działaniem ludzkiego mózgu i modelu. Przykłady:
- Precyzja. Im mniej precyzyjna instrukcja, tym model gorzej ją wykona; a człowiek “co nie dosłyszy to sobie zmyśli”
- Atencja. Komunikując się z człowiekiem możemy pewne rzeczy “podkreślić”. Modele odwzorowują to poprzez mechanizm atencji. Pod spodem mechanizm atencji to liczby (wagi, tensory, skalibrowane wskutek treningu). Ale czy nasza interpretacja komunikacji nie działa podobnie? Jeśli nikt Cię nigdy nie oszukał, to możesz być bardziej ufny, bo nie doświadczyłeś oszustwa. Nie było tego w Twoim “zestawie danych treningowych”
- Rekalibracja, Tuning. Jeśli powiedziałbym Ci pięć lat temu o “cłach” – to Twoje skojarzenie mogłoby być historyczne. Dzisiaj “cła” to temat gorący politycznie. Zmieniły się skojarzenia (i wiedza) z nimi związana, która (w pewien, nieprecyzyjnie jeszcze rozumiany przez nas sposób) jest odwzorowana w mózgu. A modele – w zależności od danych treningowych oraz późniejszego tuningu – też mogą modyfikować swoje wagi i – wskutek tego – finalne skojarzenia.
- Poisoning. Gdybym sączył Ci dezinformację i propagandę, to – zgodnie z klasykiem – kłamstwo powtarzane 1000 razy staje się prawdą. Niestety, jako ludzie tak mamy. Gdyby z kolei pozwolić modelom “przekalibrowywać” wagi podczas inferencji, to analogicznie te są narażone na tzw. “context poisoning”, który ostatecznie może dawać podobne “skutki”.
I tak dalej, i tak dalej…
Andrej Karpathy, były dyrektor ds. AI w Tesli, jeden z pionierów deep learningu i LLMów, źródło cytatów 😅 powiedział ich (cytatów) dużo, ale chciałbym przytoczyć konkretne 2:
‐ “A Large Language Model is simply a fancy autocomplete.”
Wiadomo że cytaty bywają wyjęte z – nomen omen 😅 – kontekstu. Ja bym jedynie dodał: bardzo, bardzo fancy – ale tak. A także:
‐ “The model has no real understanding of the world, it just knows how to arrange tokens coherently based on statistics.”
Statystyka?! 🤯
Tak jest!
W następnym odcinku przyglądamy się bardziej technicznie, jak to działa od środka tokenizacja, embieddingi i generowanie odpowiedzi.



