











Ostatnio omówiliśmy Big Picture Event Storming (BPES). Wiemy, jak nasz proces biznesowy wygląda z dalszej perspektywy. Następnym krokiem jest jego modelowanie, tak aby rozwiązać problemy, które zauważyliśmy wcześniej. Do tego właśnie służy kolejny etap warsztatu, czyli Process Level Event Storming (PLES).
Granica między „jest” a „chcemy, żeby było” lekko się u nas zaciera, ponieważ nie mamy jeszcze gotowego procesu. Nie zmienia to faktu, że Process Level dorzuca nowe elementy, które pozwolą lepiej zamodelować cały proces. Dzięki temu schodzimy na poziom szczegółów.
Już po Big Picture można było zauważyć w ramach całego procesu mniejsze, autonomiczne procesy. Teraz możemy skoncentrować się na każdym z nich, nie rozpraszając się na inne części systemu.
Jeśli chodzi o Process Level, przeprowadziliśmy jeszcze wspólnie z chłopakami kawałek odpowiedzialny za banowanie rekruterów. Resztę, żeby nie obciążać już ich czasowo, postanowiłem ogarnąć sam. Później ewentualne wątpliwości rozwiewałem w rozmowie z Łukaszem. W pracy na tym etapie niesamowicie pomógł mi rysunek z książki Brandoliniego:
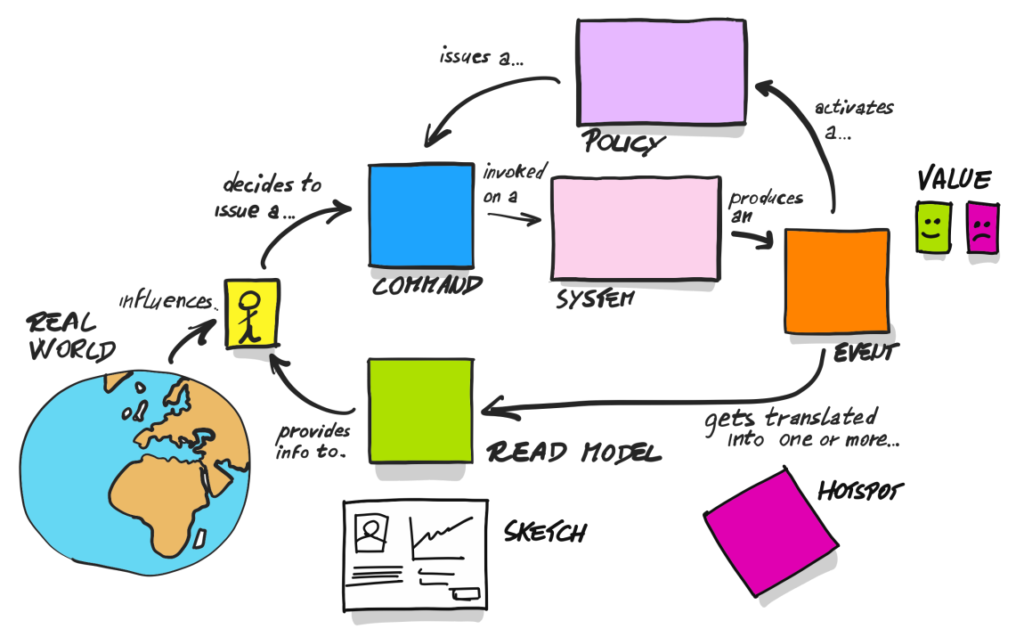
Obrazek jest opisany jako „the picture that explains everything” i całkowicie się z tym zgadzam. Widziałem go u Mariusza Gila – oprawiony w antyramę, wykonany odręcznie i podpisany przez Alberto. Nasza społeczności jest naprawdę pozytywnie geekowska. ;)
Na poziomie Big Picture operowaliśmy wyłącznie zdarzeniami, a wspomniałem wcześniej, że przy Process Level dojdą nowe elementy przydatne w modelowaniu. Są nimi te widoczne na powyższym obrazku. Zatrzymajmy się na chwilę, aby go omówić:
- Użytkownik na podstawie przesłanek/impulsu ze świata zewnętrznego decyduje się na podjęcie akcji. Przy okazji posiłkuje się informacjami dostarczonymi z systemu (read model – zielona karteczka).
- Użytkownik podejmuje akcję (komenda – niebieska karteczka), która zostanie obsłużona przez system (różowa karteczka), a w wyniku tego powstanie zdarzenie (pomarańczowa karteczka) – informacja o tym, że nastąpiła zmiana w stanie systemu.
- Po wystąpieniu zdarzenia mogą się stać dwie rzeczy:
- reakcja (polityka – fioletowa karteczka) na ten typ zdarzenia, która zaowocuje nową komendą w systemie,
- zmiany w read modelach, co może dać użytkownikowi nowe informacje do podejmowania kolejnych działań, a tym samym cykl się zamyka.
No dobra, bierzmy się do pracy! Na pierwszy ogień weźmy proces związany z draftem ogłoszenia.
Przygotowanie ogłoszenia
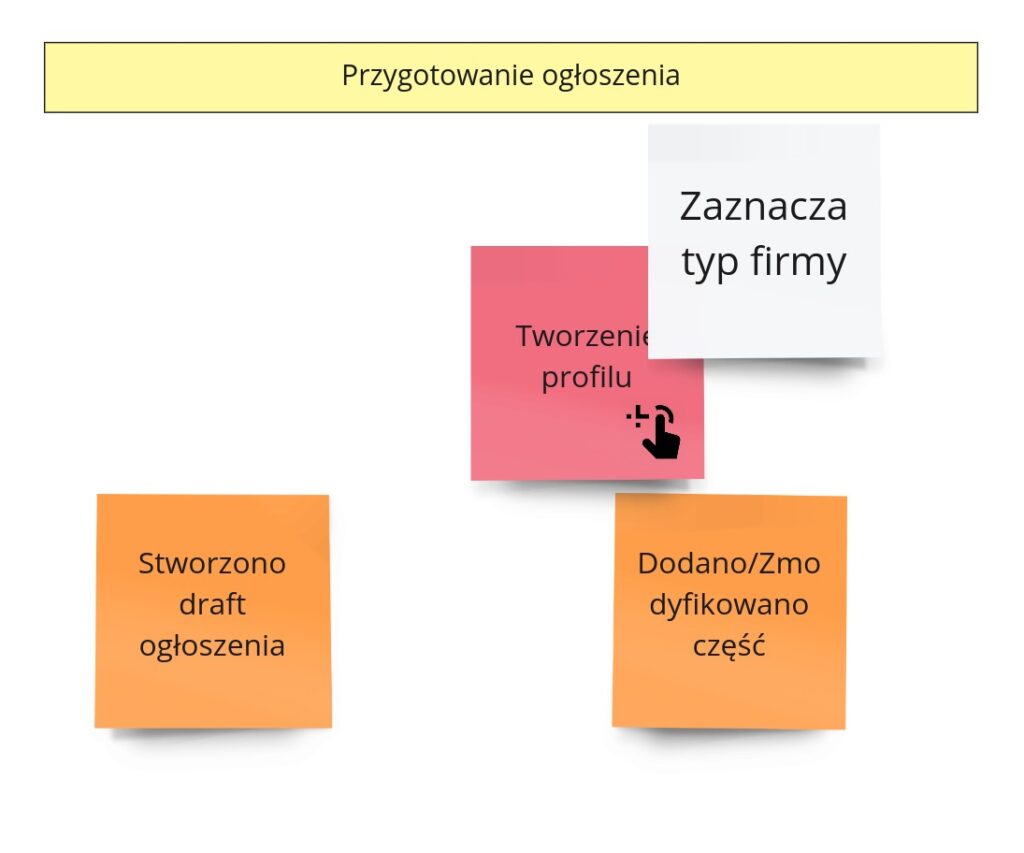
Po Big Picture proces ten wygląda następująco:
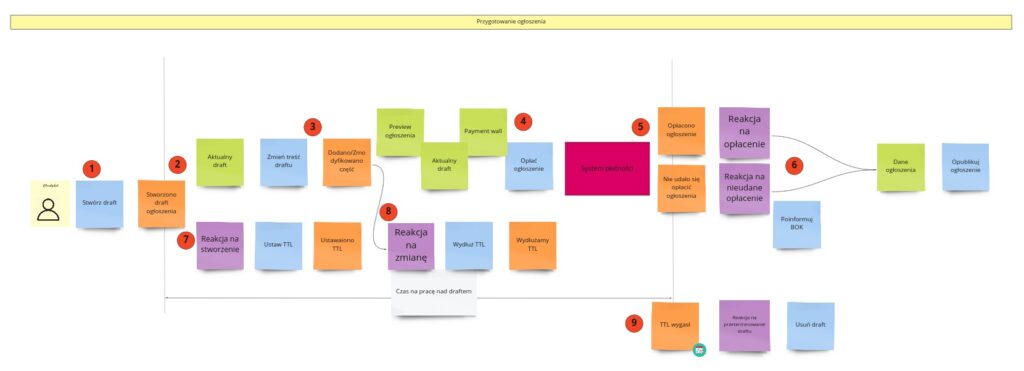
Teraz powinniśmy się zastanowić, jak chcemy, żeby ten proces wyglądał. Kto i na podstawie jakich informacji ma podejmować działania? Czy konkretne zdarzenia będą wymagały odpowiednich reakcji? Co musi się wydarzyć, aby zaistniało konkretne zdarzenie? Widzimy też hotspot, którym należałoby się zająć. Innymi słowy: próbujemy zastosować wiedzę z „obrazka wyjaśniającego wszystko” w praktyce. Tym sposobem mamy coś takiego:
Zanim omówimy, co tu się wydarzyło, chciałbym zwrócić uwagę na polityki (fioletowe karteczki). Będziemy określać je słowem „reakcja”. Mieliśmy o tym dłuższą rozmowę z Łukaszem i stwierdziliśmy, że ze względów edukacyjnych może to być dobry pomysł. Faktycznie jest to reakcja na zaistniałe zdarzenie. Brandolini w swojej książce opisuje polityki w następujący sposób:
Of course there has to be some reaction to the event. We can capture reactive logic with (lilac) Policies, like „Whenever we receive an order, we add the corresponding pizzas to the backlog”.
Głównym powodem, dla którego jednak zdecydowaliśmy się na taki zabieg, jest to, że osobom choć trochę zaznajomionym z DDD często na tym etapie Event Stormingu polityki mylą się z jednym z building blocków DDD – wzorcem strategii. Są to jednak dwie zupełnie odmienne rzeczy. Eric Evans w książce Domain-Driven Design: Tackling Complexity in the Heart of Software opisuje ten building block jako „Strategy (a.k.a Policy)”, ale w Polsce powszechnie przyjęła się właśnie ta druga nazwa. Dlatego aby podkreślić różnicę i pomóc Ci w zrozumieniu, czym są polityki w kontekście Event Stormingu, będziemy nazywać je reakcjami. Na warsztatach raczej nie spotkasz się z tym określeniem, ale najważniejsze, żeby wiedzieć, czym są, a nawet – co ważniejsze w tym przypadku – czym nie są. ;)
Wróćmy do modelowania procesu pracy nad draftem ogłoszenia. Wszystko zaczyna się, gdy programista (kandydat) podejmie akcję stworzenia draftu przez podanie jakichkolwiek danych w jeszcze pustym formularzu ogłoszenia (1). Jest to znak dla systemu, żeby zacząć zapisywać te dane, na wypadek gdyby użytkownik chciał przerwać proces i wrócić do niego za jakiś czas. Zapisanie danych z formularza możemy nazwać stworzeniem jego modelu do odczytu (2). Od teraz za każdym razem, gdy użytkownik zmieni cokolwiek w formularzu, będzie to tożsame z podjęciem akcji zmiany treści (3). Z poziomu domeny tak naprawdę nie interesuje nas, co zostało zmienione. Interesuje nas sam fakt zmiany i aktualizacja modelu draftu. Po jakimś czasie, gdy kandydat stwierdzi, że jest gotowy, na podstawie podglądu ogłoszenia i po zapoznaniu się z opcjami płatności podejmie on akcję opłacenia (4). Do gry wchodzi zewnętrzny system płatności, z którego dostajemy informację, czy transakcja się powiodła (5). Teraz dochodzimy do momentu, gdzie widać dość ciekawą decyzję biznesową (6). Otóż niezależnie od tego, czy udało się opłacić ogłoszenie, zostanie ono opublikowane. Zdecydowałem się na taki krok głównie dlatego, żeby niepotrzebnie nie komplikować procesu. W praktyce to, że z jakiegoś powodu płatność w zewnętrznym systemie się nie powiedzie, jest raczej skrajnym przypadkiem. W moim odczuciu na tyle skrajnym, że nie warto poświęcać na niego za dużo energii. Poza tym reakcją na nieudane opłacenie jest też poinformowanie Biura Obsługi Klienta o takim zdarzeniu. Dzięki temu to BOK może spróbować ponowić płatność, ściągnąć ogłoszenie lub po prostu skontaktować się kandydatem i wyjaśnić sprawę. Jeśli zauważę, że BOK dostaje dużą liczbę takich zgłoszeń albo że zajmują one za dużo czasu, wtedy rozważę zajęcie się problemem. Na coś w końcu to całe Agile się przyda. ;)
Warto też zauważyć, że w momencie stworzenia draftu powstał osobny, równolegle działający proces (7). Ma on na celu usuwanie draftów, które zalegają w systemie i nie stały się nigdy ogłoszeniami. Dajemy im jakiś czas „przydatności do spożycia” (TTL). Za każdym razem, gdy draft jest aktualizowany, reakcją na to zdarzenie jest odnowienie tego okresu (8). Jeśli czas na pracę nad draftem minie, a ogłoszenie nie zostanie opłacone, draft zostanie usunięty (9).
Rejestracja
A gdyby tak nie było rejestracji? Przecież każdy szanujący się portal musi ją mieć. W naszym przypadku przy Big Picture nawet o tym zbytnio nie myśleliśmy. Z tego powodu nie pokażę Ci, jak proces wyglądał przed Process Level Event Stormingiem. (A po nim też szału nie ma…)
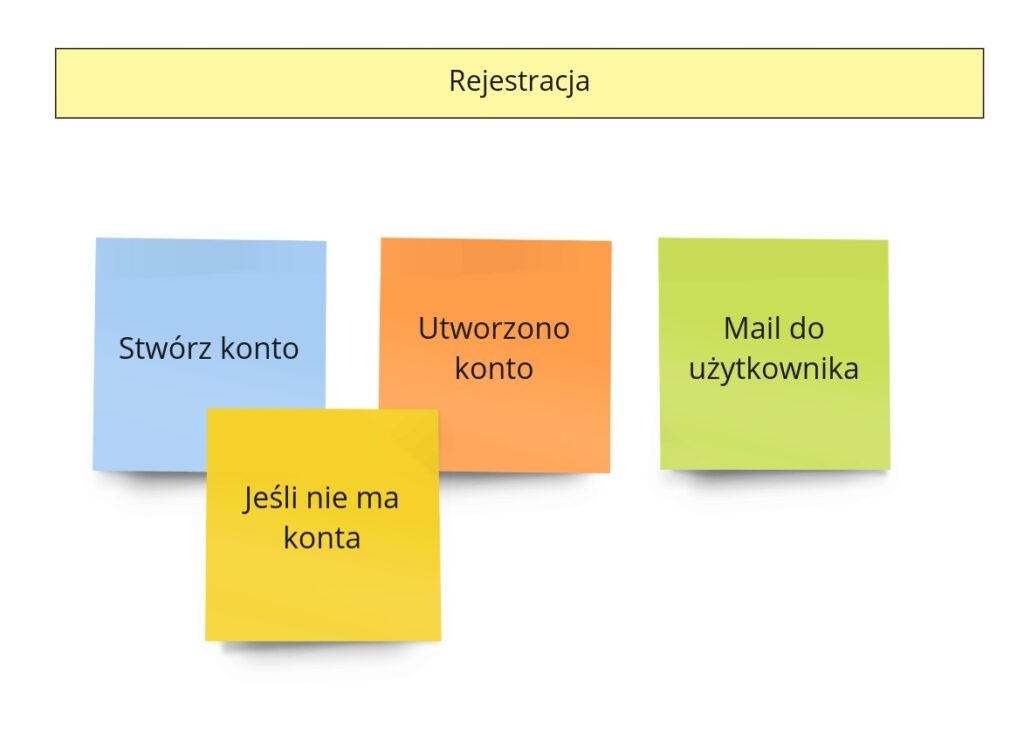
Kierując się logiką „nasz projekt jest specyficzny”, właściwie każdy ma jakąś swoją wersję osobnej aplikacji/serwisu typu „Accounts”. A tam to się dzieją rzeczy. W praktyce jednak okazuje się, że często można by zastąpić „nasze specyficzne” rozwiązanie czymś gotowym (np. Keycloak). Dlatego nie będziemy komplikować tego kawałka i nawet jeśli nie skorzystamy z czegoś gotowego, to uprościmy to do minimum.
Proces publikacji
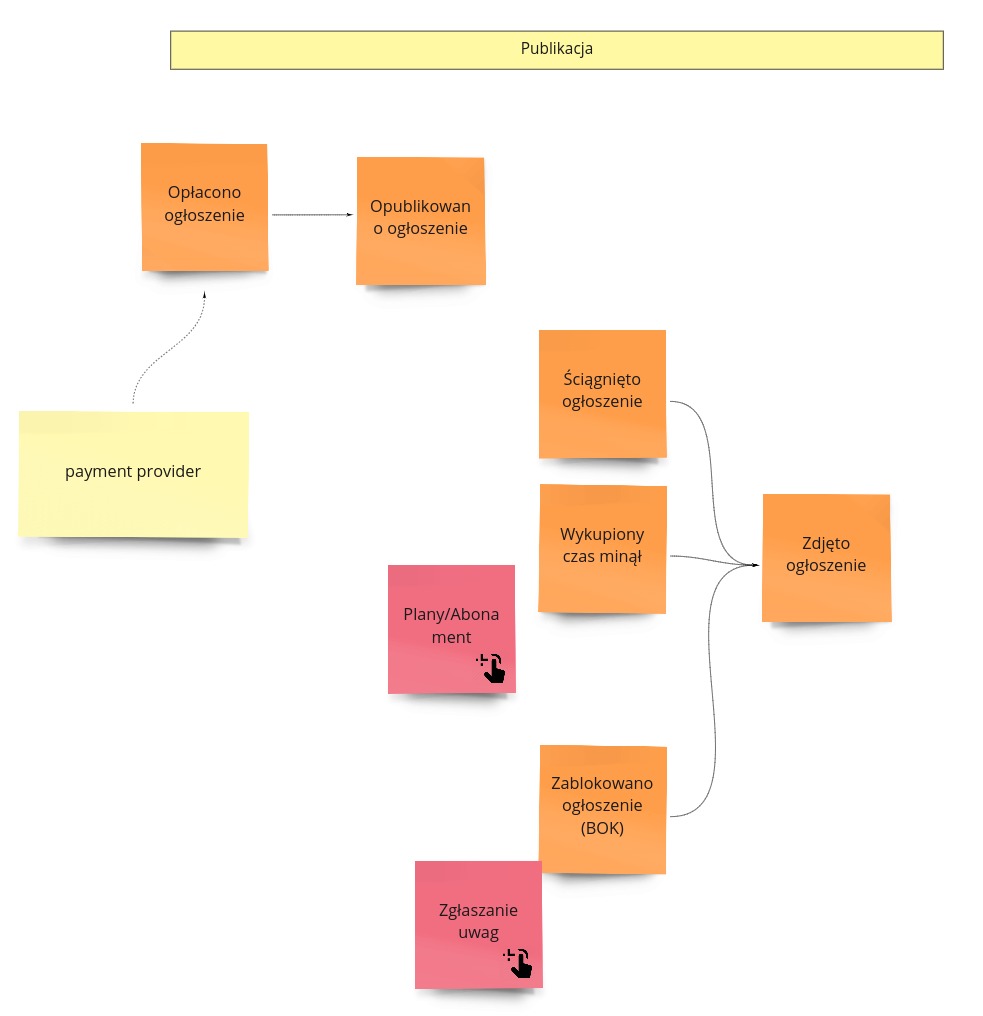
Po opłaceniu ogłoszenia następuje jego publikacja, czyli staje się ono dostępne do przeglądania w systemie. Ma ono jednak pewien cykl życia, który kończy się, gdy czas, jaki został dla niego wykupiony, minie. Zanim to jednak nastąpi, z różnych powodów ogłoszenie może zostać na chwilę „ściągnięte”, a następnie z powrotem opublikowane. Dlatego też cały ten okres postanowiłem nazwać procesem publikacji. Nieraz w przypadku, kiedy mamy do czynienia z podejściem dostępny/niedostępny, wyznacza się osobną subdomenę dostępności, ale na razie nie będziemy tego robić. Będzie to u nas subdomena publikacji.
Powtórzę jeszcze raz: po opłaceniu ogłoszenia dostajemy żądanie, aby opublikować ogłoszenie (1), na co reakcją jest to, że jest ono dostępne do wyszukiwania i wyświetlania (2). W momencie publikacji rozpoczyna się też okres, na który ogłoszenie zostało wykupione. Po jego upływie nastąpi usunięcie ogłoszenia z serwisu (3). Tutaj znowu w celach uproszczenia pomijamy przypadki przedłużenia tego okresu, tworzenia nowych ogłoszeń na podstawie starych itd.
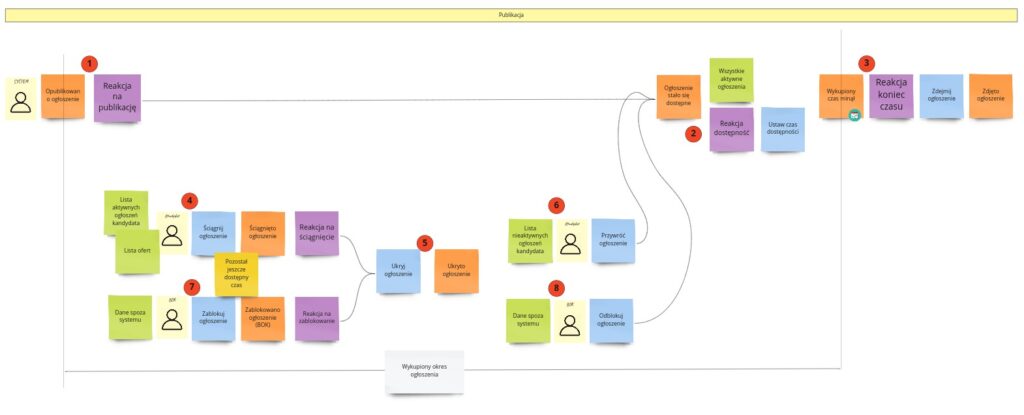
Zastanówmy się, co może nastąpić w okresie, na który ogłoszenie zostało wykupione. Można tu wyróżnić dwie sytuacje:
- Kandydat może zdecydować się na ściągnięcie ogłoszenia. Na przykład kiedy stwierdzi, że ma ich za dużo, albo otrzymał wystarczającą liczbę ofert (4). Gdy kandydat podejmie taką akcję, to zanim ogłoszenie zostanie ściągnięte, powinna zostać sprawdzona reguła biznesowa mówiąca o tym, czy ogłoszeniu pozostał jeszcze jakikolwiek czas. Po co w ogóle zaczynać ten proces, jeśli ogłoszenie i tak zostało zdjęte permanentnie? W przeciwnym wypadku ukrywamy je (5), co powoduje, że zostaje zaktualizowana lista nieaktywnych ogłoszeń. Na jej podstawie kandydat może podjąć decyzję, czy chce przywrócić ogłoszenie (6).
- Innym przypadkiem, kiedy ogłoszenie może być chwilowo niedostępne, jest ściągniecie go przez BOK. Proces wygląda bardzo podobnie, ale występują tu inne osoby i decyzje podejmowane są na podstawie innych przesłanek czy danych. Ściągnięcie ogłoszenia może nastąpić na przykład po tym, jak BOK dostanie informację dotyczącą jakiegoś problematycznego ogłoszenia (7). Jego przywrócenie może nastąpić na przykład po wymianie mailowej lub rozmowie telefonicznej z ogłoszeniodawcą (8). Innymi słowy – będą to dane spoza systemu. Przynajmniej na razie.
Warto też zauważyć, że w obu przypadkach przestajemy liczyć czas, na jaki ogłoszenie zostało wykupione. Zaczynamy go skracać dopiero wtedy, gdy staje się ono znowu dostępne.
Dla przypomnienia: tak proces ten wyglądał po Big Picture:
Proces wyszukiwania
Przy modelowaniu procesu może się okazać, że coś, co w Big Picture było zdarzeniem, tak naprawdę nim nie jest. U nas dobrym przykładem jest „Wyszukano ogłoszenie”.
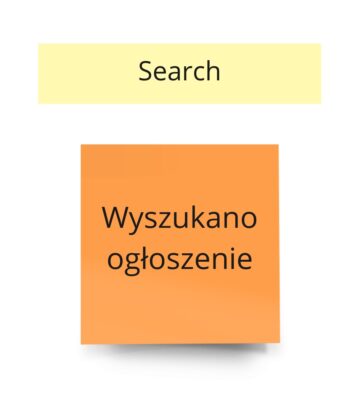
Wyszukiwanie w naszym przypadku nie ma nic wspólnego ze zmianą stanu systemu. Tu rekruter na podstawie dostępnych filtrów odpytuje system o listę ogłoszeń (read model) spełniających konkretne kryteria. Dlatego też postanowiliśmy przedstawić to w następujący sposób:

Ofertowanie
Przechodzimy teraz do kluczowego procesu – ofertowania. Jest to ten element układanki, który odróżnia nasz pomysł od zwykłego portalu z ogłoszeniami. Tutaj osoba przeglądająca ogłoszenie, żeby móc złożyć ofertę, musi zaakceptować wszystkie warunki ogłoszenia. Następnie sama oferta może zostać przeczytana, odrzucona, albo dodana do ulubionych.
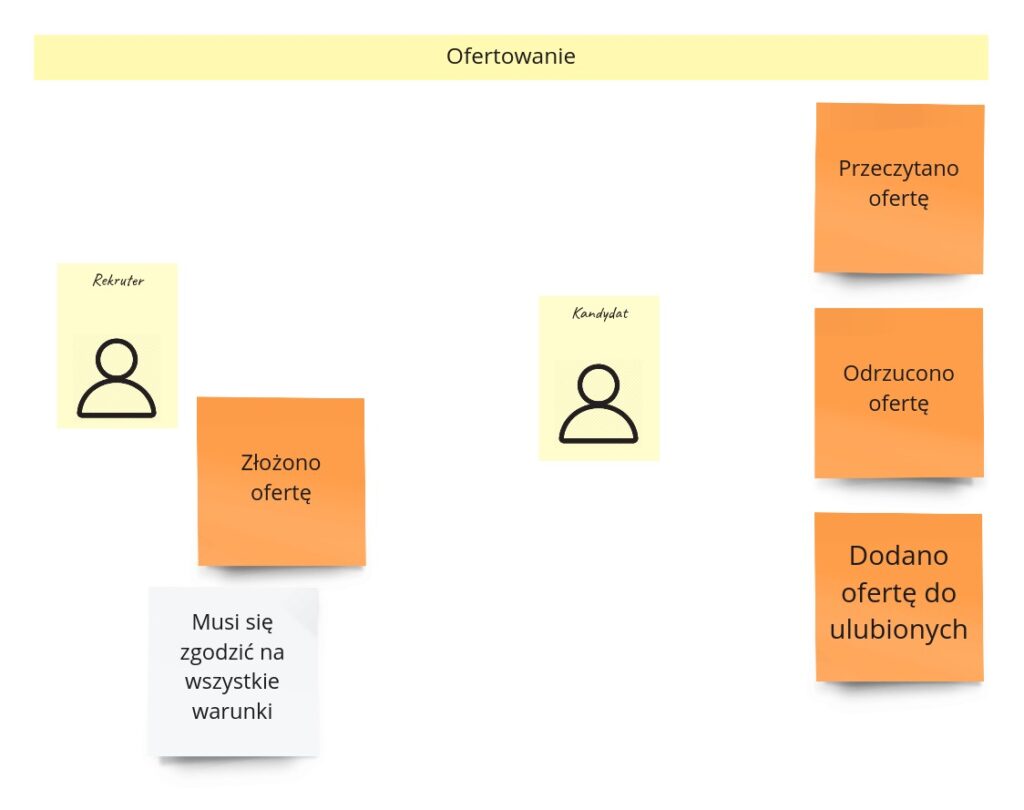
Po sesji modelowania proces ten prezentuje się tak:
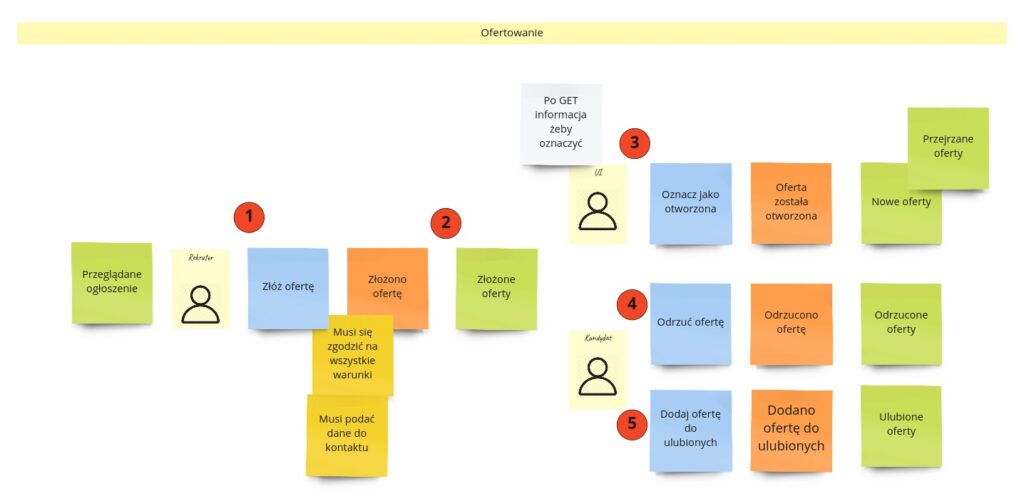
Wszystko zaczyna się na stronie ogłoszenia. Rekruter, który je przegląda, może złożyć ofertę (1). Istotne jest to, że musi zaakceptować wszystkie warunki ogłoszenia i podać dane kontaktowe. Jeśli to zrobi, oferta zostaje złożona, a tym samym trafia na widok z ofertami w panelu kandydata (2). Ten widok może być źródłem wielu akcji, a najciekawszą z nich z poziomu modelowania jest „Oznacz jako otworzona” (3). Zauważ, że jej źródłem jest UI. Dlaczego? Otóż nowe oferty będą w jakiś sposób oznaczone jako… nowe – nieprzeczytane. Sam użytkownik nie będzie podejmował tej akcji. Gdy zobaczy nową ofertę, kliknie w nią, aby zapoznać się z jej szczegółami. To nie jest coś, co zmieni stan systemu, bo w tym przypadku co najwyżej odpytujemy (zapytanie, nie komenda) o szczegóły oferty. Moglibyśmy nawet tego nie robić, jeśli mielibyśmy już je wcześniej na widoku. Dlatego właśnie to UI po otworzeniu oferty (można tu wprowadzić jakieś opóźnienie, np. sekundę) decyduje o wysłaniu komendy, która ma spowodować zmianę stanu oferty na „otworzona”/„przejrzana” (nie „nowa”). Funkcjonalność dokładnie taka sama jak w klientach pocztowych.
Inne akcje podjęte na podstawie widoku złożonych ofert inicjuje już sam kandydat. Może on odrzucić ofertę (4), przez co wpadnie ona na widok tych odrzuconych, albo dodać do ulubionych (5).
Weryfikacja kandydata
Już przy Big Picture ten proces okazał się ciekawy pod względem tego, że odsialiśmy w nim wiele zdarzeń, które tak naprawdę były zdarzeniami zewnętrznego systemu do weryfikacji. Dla przypomnienia – ostatecznie proces ten po Big Picture prezentuje się tak:
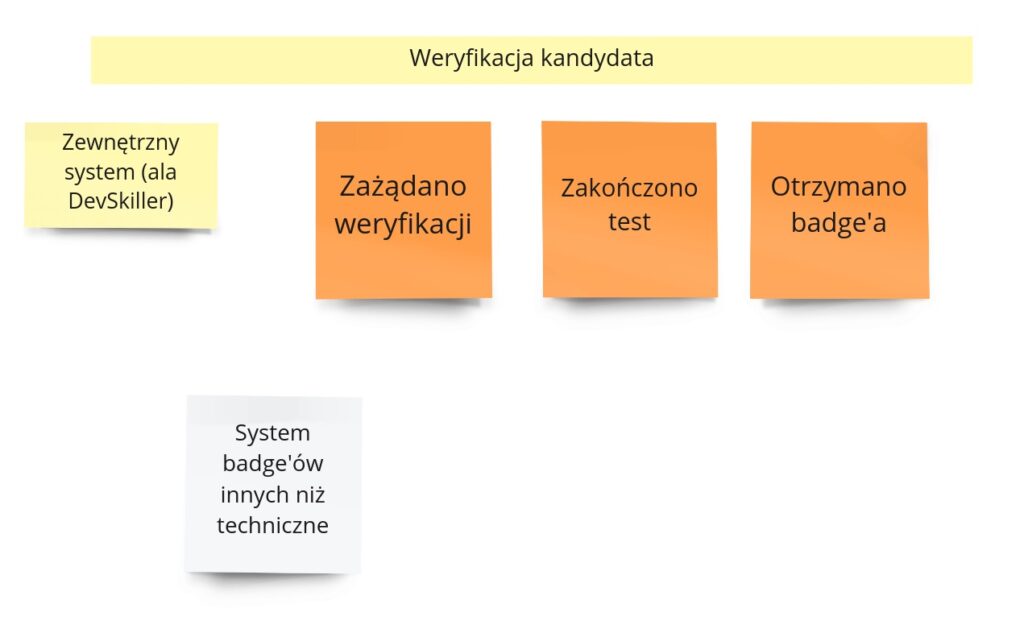
Zauważ, że jest tu założenie, że system zewnętrzny poinformuje nas o zakończeniu testu. Ponadto w systemie odnotowujemy moment żądania weryfikacji (składanego przez kandydata chcącego potwierdzić swoje umiejętności), którego celem było zaznaczenie rozpoczęcia procesu weryfikacji w zewnętrznej usłudze. Dlatego sensowne wydawałoby się wprowadzenie po naszej stronie okresu, jaki dajemy użytkownikowi na rozwiązanie testu. To wszystko zaczyna brzmieć dość skomplikowanie. Mamy tu bardzo mocne przywiązanie do zewnętrznej usługi oraz pewnych założeń co do udostępnianych przez nią funkcjonalności. Stało się to jeszcze bardziej widoczne przy PLES, dlatego trzeba było pomyśleć o czymś prostszym, i tak oto dochodzimy do następującego rozwiązania:
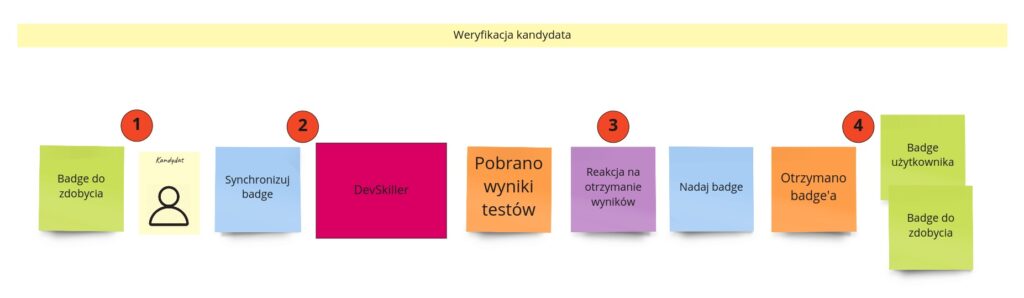
W tym podejściu właściwie nie mamy żadnych założeń co do zewnętrznego systemu poza tym, że udostępnia linki z testami, jakie można przejść, oraz API z testami, jakie wykonał konkretny użytkownik. Dzięki temu możemy pokazać kandydatowi widok z badge’ami do zdobycia (1). Każdy z nich jest podlinkowany do testu w zewnętrznym systemie, więc użytkownik może tam przejść i go rozwiązać. Cały proces weryfikacji odbywa się poza naszym systemem i nie obchodzi nas zupełnie, ile czasu to zajmuje. Po rozwiązaniu testu użytkownik wraca i inicjuje akcję synchronizacji (2), co wiąże się z zapytaniem zewnętrznego API o testy użytkownika. Po otrzymaniu wyników sprawdzamy, czy są wśród nich nowe, które pozwalają na nadanie konkretnych badge’y (3). Jeśli tak, to je nadajemy, co ostatecznie skutkuje zmianami w widokach badge’y użytkownika oraz tych, które może jeszcze zdobyć (4).
Proces banowania rekrutera
Na koniec zostawiliśmy proces, który wydał nam się najciekawszy, i tak naprawdę modelowaliśmy go jako pierwszy jeszcze wszyscy razem.
W Big Picture wyglądał on następująco:
A w PLES rozwinął się do takiej formy:
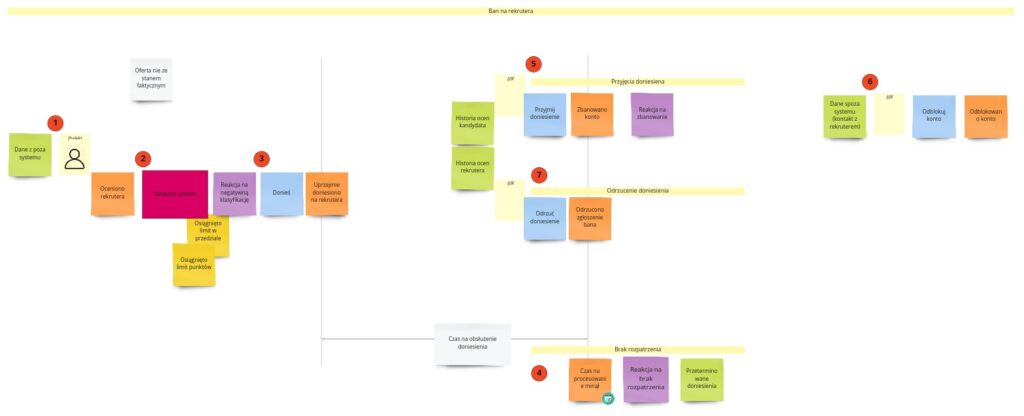
Po udanym (lub nieudanym) procesie rekrutacyjnym chcemy dać programiście możliwość ocenienia oferty, a tym samym osoby, która ją złożyła. Zakładamy, że impulsem do oceny może być coś, co pochodzi spoza systemu (1). Może to będzie mail z innego systemu z prośbą o ocenę czy refleksja, że oferta całkowicie rozminęła się z rzeczywistością. Na podstawie swoich doświadczeń kandydat ocenia rekrutera, a ocena ta trafia do jakiegoś systemu rankingowego (2), przez co ogólna ocena konkretnej osoby wzrasta lub spada. Jeśli spadnie ona poniżej określonego progu, następuje „uprzejme doniesienie” (3) na rekrutera do naszego BOK-u. W tym momencie proces może pójść trzema ścieżkami:
- Doniesienie będzie miało jakiś czas na rozpatrzenie (4). Jeśli BOK się nim nie zajmie w tym okresie, nastąpi reakcja na brak rozpatrzenia. U nas trafi ono po prostu na listę przeterminowanych zgłoszeń. Dzięki temu możemy później pomyśleć, czy nie wprowadzić jakiegoś rodzaju notyfikacji, gdy tego rodzaju zgłoszeń będzie dużo albo gdy pojawi się nowe.
- Zgłoszenie zostaje rozpatrzone w dostępnym na to czasie. BOK zarówno na podstawie historii ocen kandydata, jak i historii zgłoszeń dotyczących konkretnego rekrutera może podjąć jedną z dwóch decyzji:
- Zbanować rekrutera (5) – w wyniku czego rekruter dostanie o tym informację (prawdopodobnie mailowo) z ewentualnymi danymi kontaktowymi, jeśli chciałby odnieść się do tego. W takim przypadku po kontakcie z BOK-iem konto rekrutera może zostać odblokowane (6).
- Odrzucić zgłoszenie (7) – może to nastąpić przykładowo w momencie, gdy BOK po zapoznaniu się z historią ocen wystawianych przez kandydata zauważy, że może to być celowe zaniżanie ocen rekrutera.
Tak zamodelowany proces banowania jest generyczny. Mam tu na myśli to, że wiele procesów z różnych domen może tak właśnie wyglądać. W takiej samej formie mógłby tak naprawdę służyć ocenie czegokolwiek. Co ciekawe, praktycznie tak samo mógłby być zamodelowany proces reklamacji. Wtedy można by było pominąć system rankingowy, a złożenie reklamacji przez klienta byłoby „uprzejmym doniesieniem” na źle ssący odkurzacz.
Gratulacje!
Odwaliliśmy dzisiaj kawał dobrej roboty. Bez zbędnego pitu, pitu, przeszliśmy krok po kroku przez wszystkie procesy i zamodelowaliśmy je tak, jak chcielibyśmy, żeby wyglądały. Wprowadziliśmy nowe elementy, dzięki czemu przepływy procesów stały się szczegółowe, co pozwoliło na zweryfikowanie niektórych wcześniejszych założeń, tak jak przy procesie weryfikacji kandydata. Good job!
Założę się, że wiele projektów przy modelowaniu procesów skorzystałoby na warsztatach Event Stormingu, dlatego koniecznie podziel się tym postem z innymi!
Następnym razem siadamy już do Design Level Event Stormingu…
Do przeczytania!




