











Testy jednostkowe to potężne programistyczne narzędzie. Swego czasu były postrzegane jako “lek na całe zło”. Potem: jako balast. Okazało się, że to nie takie proste, jak się na pierwszy rzut oka wydaje.
Faktem pozostaje jednak, że odpowiednio i świadomie wykorzystane bardzo pomagają w procesie tworzenia i rozwijania oprogramowania. Ale, co mniej oczywiste – mogą też zaszkodzić!
A suite of good unit tests is immensely valuable (…)
However, a suite of bad unit tests is immensely painful.
Steve Sanderson

Czy pisanie testów jest łatwe? Zdecydowanie nie. Ale to jedna z kilku uniwersalnych programistycznych umiejętności, w którą warto zainwestować. Wymaga to dużo praktyki, czasu, nauki i wyciągania wniosków z błędów. Jednak na dłuższą metę: bardzo się opłaca. A dodatkowo może być naprawdę przyjemne! Po wskoczeniu na pewien level znajomości tematu – nie wyobrażamy sobie programowania bez nich.
Niniejszy tekst to niezła kobyła, ale i tak ledwo muśniemy tutaj powierzchnię tematu. To bardzo dobry start i znajdziesz tu coś dla siebie, niezależnie od poziomu Twojej wiedzy.
Zacznijmy od oczywistego wstępu, czyli:
CO TO SĄ TESTY JEDNOSTKOWE?
Definicje testów jednostkowych można mnożyć. Ja na przestrzeni lat ukułem taką:
Test jednostkowy to kod wykonujący inny kod w kontrolowanych warunkach w ramach jednego procesu w pamięci, w celu weryfikacji (bez ingerencji programisty), że testowana logika działa w ściśle określony sposób.
I każde słowo ma w tej definicji znaczenie:
“Kod wykonujący inny kod” – rozdzielamy kod testów od kodu produkcyjnego; nie zapominamy jednak, że o każdy kod trzeba dbać (będzie o tym dalej).
“w kontrolowanych warunkach” – test daje taki sam rezultat niezależnie od środowiska / maszyny / setupu (będzie o tym dalej), w czym pomaga założenie:
“w ramach jednego procesu w pamięci” – testy jednostkowe są szybkie, powtarzalne i odizolowane od wszystkich innych operacji (będzie o tym dalej)
“w celu weryfikacji” – testy COŚ sprawdzają i jawnie definiują ten aspekt (będzie o tym dalej)
“(bez ingerencji programisty)” – testy działają automatycznie (będzie o tym dalej)
“testowana logika działa w ściśle określony sposób” – czy to oznacza, że testy eliminują występowanie błędów? I o tym też będzie dalej!
JAKA JEST ROLA TESTÓW JEDNOSTKOWYCH?
Wyżej napisałem, że testami można sobie zaszkodzić. Zatem: czy warto z nich korzystać?
Gdyby nie było warto, tobym nie publikował tego tekstu ;) . Koszt NIEPISANIA testów jest za duży, by go zaakceptować. Szczególnie jeśli weźmiemy pod uwagę korzyści płynące z różnych ról, jakie testy jednostkowe odgrywają w naszych systemach.
Let’s see:
Weryfikacja działania bez uruchamiania systemu
Oczywiste, prawda? To przecież podstawowa funkcja testów i każdy jest jej świadom! Jednak za chwilę nawet tutaj natkniemy się na pewien plot twist.
Ciągłe ręczne sprawdzanie działania aplikacji to straszna strata czasu. Trzeba poczekać na odpalenie serwera, rozgrzanie systemu. Trzeba przeklikać się przez interfejs i badać rezultat.
Manual testing is not just dumb, it’s immoral.
Robert C. Martin (Uncle Bob)
Dobre testy mogą tutaj bardzo pomóc!
Dzięki automatycznej weryfikacji, że testowany kod spełnia pewne założenia, nie musimy uruchamiać całego systemu. Wystarczy włączyć testy i poczekać chwilę na ich wykonanie.
Zielony pasek w test runnerze oznacza jedną z dwóch rzeczy: albo nasz kod działa, jak powinien (hurra!), albo mamy źle napisane testy (buuu).
Innej możliwości nie ma.
Sposób działania testów jest dość banalny:
- autor testu (programista) dostarcza dane wejściowe (input),
- test wykonuje instrukcje i…
- sprawdza, czy rezultat działań (output) jest zgodny z oczekiwaniami.
Z czasem, gdy wraz z nabywaniem praktyki testy będą miały coraz większą wartość, zaufanie do nich będzie rosło. Możemy nawet dotrzeć do poziomu, na którym wystarczy jedno uruchomienie “na wszelki wypadek”, po zakończeniu implementacji całego ficzera.
Zatem: czy testy eliminują powstawanie błędów?
To właśnie wspomniany plot twist… Otóż: niekoniecznie!
Zgodnie z ustaloną wcześniej definicją: testy to po prostu kod. Kod testujący i kod testowany są napisane przez takiego samego programistę (a najczęściej tę samą osobę).
Bardzo często wchodzimy w świat testów z oczekiwaniem, że testy wyeliminują bugi w systemie. Niestety jest to błędne założenie. A potem z rozczarowaniem stwierdzamy, że tak się nie dzieje, i zniechęceni zamykamy temat.
Już na początku przygody z testami trzeba zaakceptować smutny fakt:
Testy weryfikują, że kod działa tak, jak chce tego programista, a nie tak, jak powinien!

Owszem, testy MOGĄ zredukować liczbę błędów. Jednak traktujmy to jako miły efekt uboczny, bo do tego celu potrzebne jest spełnienie dwóch warunków.
Warunek pierwszy: programista musi umieć pisać dobre testy (bo, jak wspomnieliśmy wyżej, złe testy mogą być szkodliwe).
Warunek drugi: programista musi rozumieć specyfikację zgodnie z intencjami jej autorów. Specyfikację napisaną dokładnie, precyzyjnie i klarownie. Poprzedzoną porządną analizą wymagań i wykryciem przypadków brzegowych. A wiemy przecież – i ja i Ty – że to często nie jest normą.
Podsumowując: testy nie gwarantują wyeliminowania bugów. Ale mogą znacznie zredukować prawdopodobieństwo błędów regresji (czyli wprowadzanie usterek do działającego oprogramowania).
Co prowadzi nas do kolejnego punktu:
“Safety net”: zabezpieczenie przed regression bugs
Od samego początku swojej testowej drogi (2007 rok!) podchodziłem do testów z wielkim zaufaniem i traktowałem je jako zapewnienie, że po zmianach kod nadal działa, jak powinien. No bo przecież “pasek test runnera zaświecił się na zielono”. Niestety, nie zawsze tak było. Ale wina leżała oczywiście wyłącznie po mojej stronie.
Prawda jest taka, że świetne testy chronią przed bugami przy zmianach w kodzie. Ale nauka pisania testów trwa i wymaga praktyki. Jednak, gdy już nauczymy się pisać testy tam gdzie trzeba i tak jak trzeba, zmiany w istniejącym kodzie będą o wiele łatwiejsze. Wchodzimy w legacy code jak nóż w masło (a często kod staje się legacy już w momencie napisania, co nie?).
Na pewnym poziomie możemy liczyć na to, że testy (nie tylko jednostkowe) wychwycą niechciane konsekwencje zmian. Czyli modyfikujemy kodzik z dużą dozą prawdopodobieństwa, że wprowadzamy tylko świadome zmiany i unikamy efektów ubocznych.
Gdy popełnimy błąd – testy to wychwycą. Muszą jednak spełniać ten najważniejszy warunek – muszą być dobre (cokolwiek to w tym momencie znaczy). W przeciwnym wypadku doświadczenia będą zgoła odmienne.
Słabe lub niepotrzebne testy utrudniają utrzymanie i rozwój systemu.

A niespodziewane zmiany to nie tylko nasza własna ingerencja! Może to być również modyfikacja wykonana przez innego członka zespołu. Albo zmiana w środowisku. W bazie danych. W zewnętrznej bibliotece (po podbiciu wersji). Czy nawet w zewnętrznym systemie, z którym się komunikujemy.
W tych przypadkach ponownie wychodzimy poza obszar testów jednostkowych… ale to nic. Mechanizmy nauki pisania innych testów są podobne, zmienia się tylko kontekst.
Wyzwoliciel spod Klątwy Debuggera
Jedna z moich ulubionych korzyści płynących z pisania testów to możliwość debugowania wybranego elementu systemu bez uruchamiania całości. Możemy podpiąć debugger w kontekście jednego konkretnego testu, skonstruowanego pod jeden konkretny scenariusz, i cieszyć się śledzeniem wykonywanej pod spodem logiki bez oczekiwania na “wstanie i rozgrzanie” całego środowiska.
To niesamowicie przyspiesza proces identyfikacji i poprawiania usterek!
Ale dodatkowo ciekawym efektem rozwoju umiejętności pisania testów jest też stopniowa redukcja czasu spędzanego w debuggerze.
Nie lubisz debugować?
Naucz się pisać porządne testy!
Zobaczysz, że w miarę postępów w nauce tworzenia testów, coraz rzadziej będziesz korzystać z debuggera. Dla mnie była to wielka niespodzianka, którą powitałem z ogromnym entuzjazmem.
Dokumentacja
Tworzenie dokumentacji do kodu to często strata czasu. Powód tego jest bardzo prosty: taka dokumentacja nadaje się do czegokolwiek tylko w momencie jej pisania. Po kilku dniach, tygodniach, miesiącach ma się nijak do opisywanego kodu. Chyba, że ktoś faktycznie dba o jej uaktualnienie, ale… No właśnie, dbasz?
Mówi się, że najlepszą dokumentacją kodu powinien być sam kod. Self-documenting code. I jest to prawda! A testy mogą być w takim wypadku BARDZO pomocne!
Testy to kod – więc są czytelne dla programisty.
Testy są regularnie uruchamiane – więc są zsynchronizowane z testowaną logiką.
Mało tego: testy nieustannie ewoluują. Rozwijają się wraz z systemem oraz zespołem! Z czasem tworzą coraz bardziej precyzyjną i coraz lepszą narrację dla produkcyjnych instrukcji.
W tym miejscu pokuszę się nawet o stwierdzenie, że testy transformują “życzenie” klienta w prawdziwe “wymaganie”. Bo są wykonywalną dokumentacją.
Testy zmieniają desirement w requirement.

“Desirement” to tylko “chcenie”. ŻYCZĘ SOBIE, by system działał jakoś… ale nie mam na to gwarancji (poza słowem programisty).
“Requirement” to faktyczne wymaganie, zapisane za pomocą testu. Jeśli failed tests będziemy traktować tak poważnie jak błędy kompilacji, to będą one czynnikiem eliminującym możliwość wdrożenia danego builda. A to już jest konkretna korzyść i gwarancja, że nie tego elementu nie pominiemy.
Sprawdzian dla specyfikacji
Wspominaliśmy wcześniej, że testy mają szansę eliminować występowanie błędów wtedy, gdy specyfikacja jest napisana porządnie i gdy programista rozumie ją tak samo jak autor.
I w tym kontekście również testy przychodzą z pomocą. One challengują dostarczone wymagania (albo “życzenia”) klienta. Możemy przygotowywać się do implementacji wybranej funkcji poprzez napisanie całej baterii testów definiujących pożądane zachowania. Wówczas, przed trybem “implementacji”, znajdujemy się w trybie “analizy”. Za pomocą kodu chcemy zamodelować wszystkie możliwe scenariusze. I wtedy też wykryjemy wiele braków w wymaganiach.
Ma to bardzo pozytywną konsekwencję: programista może te braki zgłosić przed napisaniem nawet linijki produkcyjnego kodu. Lepiej jest dopytać i poprosić o doprecyzowanie wymagań, niż zgadywać podczas programowania i robić błędne założenia.
Umówmy się: często decyzje czysto produktowe/funkcjonalne nie powinny być podejmowane przez programistę. Dzięki testom możemy dostarczyć klientowi (kimkolwiek by był) bardzo wczesny feedback o wybrakowanej specyfikacji.
Narzędzie do komunikacji
Dokumentacja i specyfikacja to nie wszystko. Testy świetnie nadają się również do mniej formalnej komunikacji między programistami!
Testy opisują działanie kodu oraz – co ważne! – intencje autora. A te intencje można zawsze zweryfikować poprzez odpalenie testów. Zatem nawet w przypadku zawiłego kodu, zrozumienie go może stać się o wiele łatwiejsze dzięki testom. One dokumentują decyzje podjęte na etapie programowania.
Czyli <fanfar />:
Testy mogą zastąpić komentarze w kodzie (sic!)
Zamiast pisać komentarz: “ten kod się wywali, jeśli podstawisz 3 zamiast 1 pod X, bo…” – piszemy testy. Jeden pod X podstawi 1 i wykona się jak trzeba. Drugi pod X podstawi 3 i będzie oczekiwał wyjątku. Ów drugi test nazywamy tak, aby nie było wątpliwości, skąd bierze się zachowanie systemu (o nazwach będziemy jeszcze mówić poniżej).
Wspominając o “komunikacji między programistami” mam na myśli również bardzo ważną komunikację ze sobą samym. “Ja – piszący kod” i “ja – czytający kod” to dwie różne osoby, mimo że w tym samym ciele ;). Dzieli nas czas, doświadczenie i kontekst.
Testy sprawdzają się doskonale także jako notatki na przyszłość. Nie masz w danej chwili czasu, by zaimplementować genialny pomysł? To nie problem: napisz test, by zostawić po tym pomyśle ślad w swoim kodzie… i oznacz go jako test ignorowany! Taki test nie będzie wykonywany, a dzięki odpowiedniej nazwie wskaże Twoje założenia i drogę na przyszłość.
I jeszcze jeden aspekt, możliwy do zaobserwowania szczególnie w środowisku open source (choć sprawdzi się także w “normalnej” pracy). Jeżeli używamy cudzej biblioteki i działa ona nie do końca zgodnie z naszymi oczekiwaniami, najlepszym sposobem zademonstrowania tej niezgodności będzie właśnie czerwony (nieprzechodzący) test.
“Send me a failing test”
Jeśli jesteśmy w stanie napisać taki pokazowy test, to dyskusja wchodzi na zupełnie nowy poziom.
Poprawa designu aplikacji
Dochodzimy do aspektu, który bardzo kocham w testach. Mogą one bowiem – jeśli odpowiednio do nich podejdziemy – znacznie poprawić design aplikacji. Nie chodzi oczywiście o jej wygląd (UI), ale o strukturę i architekturę.
Każdy testowany komponent musi udostępniać pewne API, wystawiać swoje funkcje na zewnątrz. API jest wykorzystywane zarówno przez testy, jak i przez inne komponenty składające się na całość systemu.
Stosowanie testów jednostkowych (szczególnie w kontekście TDD, ale do tego jeszcze dojdziemy) wymusza na programiście chwilę refleksji… Zamiast z pasją, zaangażowaniem, ale często (znam to z doświadczenia) bez odpowiedniego przemyślenia rzucać się w wir kodowania, twórca kodu najpierw oddaje się “krótkiej zadumie”. Ten namysł nad przyszłą implementacją – czyli nad NIEnapisanym jeszcze kodem – jest kluczowy.
Jak najlepiej to zrobić, żeby nie tylko działało, ale jeszcze było testowalne? Jak rozplanować odpowiedzialności pomiędzy klasy/komponenty? Gdzie dodać interfejs? Jakich zależności potrzebuję? Jak całość wpasuje się w już istniejący kod? I co tak naprawdę muszę napisać, żeby spełnić wymagania, nie marnując czasu na pieszczenie się z niekoniecznym kodem?
Taka chwila pozwala zrozumieć prawdziwą potrzebę programowania. Dzięki temu dobrany sposób realizacji ma szansę być tym najbardziej optymalnym i efektywnym.
Dodatkowo:
Stosowanie (dobrych) testów jednostkowych
implikuje wykorzystanie zalecanych praktyk programistycznych.
U mnie zainteresowanie testami jednostkowymi rozpoczęło dawno temu całkiem nowy rozdział w dev-przygodzie.
Wtedy dotarło do mnie, po kiego grzyba stosować programowanie pod interfejs/kontrakt. Wtedy też zrozumiałem, że klepanie kolejnych linii “tylko działającego” kodu ma krótkie nogi i można to zrobić lepiej. Doceniłem praktyczną wartość Inversion of Control i innych praktyk przydatnych w codziennej programistycznej pracy.
Tym samym dochodzimy do wniosku: trudny do przetestowania kod można napisać lepiej. Jasne, KAŻDY bez wyjątku kod można napisać lepiej, ale trudność testowania może być wskaźnikiem obszarów żebrzących o refactoring.
Kod trudny do przetestowania jest kodem trudnym do utrzymania.
Jakie best practices mogą zostać WYMUSZONE przez pisanie testów w odpowiedni sposób? Proszę bardzo, poniżej skromna lista:
- SOLID principles
- DRY – Don’t Repeat Yourself
- KISS – Keep It Simple, Stupid!
- YAGNI – You Ain’t Gonna Need It
- IoC / DI – Inversion of Control / Dependency Injection
A co najlepsze: to po prostu wchodzi w krew. Im więcej praktyki, tym trudniej będzie napisać słaby kod. True story!
Narzędzie do nauki i eksploracji
Czy zdarza Ci się pisać “jednorazowe”, tymczasowe aplikacyjki konsolowe tylko w celu sprawdzenia jak działa jakiś system lub biblioteka? No to… nigdy więcej!
Takie aplikacje są potrzebne i wartościowe. A my je często po prostu kasujemy! Jak wiele doświadczenia wtedy przepada? Można zrobić to lepiej, zachowując zdobytą wiedzę w kodzie i commitując do repozytorium. Dzięki temu będziemy mogli do niej wrócić. I to nie tylko my, ale także cały zespół. I przyszłe pokolenia ;).
Takie zabawy i eksperymenty, zrealizowane oczywiście za pomocą testów, to po prostu część naszego projektu. Możemy stworzyć dedykowany folder na wybraną integrację i hulaj dusza!
W przypadku używanej biblioteki robimy coś – teoretycznie – dziwnego: dopisujemy testy do cudzego kodu! A po co? Otóż dzięki temu lepiej rozumiemy jej działanie. I sprawdzamy, czy taka biblioteka na pewno działa tak, jak nam się wydaje na podstawie dokumentacji (która – jak już wiemy z poprzednich akapitów – może być “rozjechana” z prawdziwym, żyjącym kodem).
A w bonusie otrzymujemy jeszcze jedną bardzo ważną charakterystykę, pasującą do poruszanego wcześniej tematu: regression bugs. Dzięki takim testom upewniamy się, że używany komponent działa tak samo – w kluczowych dla nas aspektach – także po aktualizacji i zmianie jego wersji! Bardzo, BARDZO przydatna świadomość i “siatka bezpieczeństwa”.
A jeśli bawimy się nie cudzą biblioteką, tylko zewnętrznym systemem, to oczywiście wychodzimy poza zakres testów jednostkowych, mocząc paluchy w testach integracyjnych. Ale to nic, bo zasada działania jest taka sama. A korzyści nawet większe, bo o ile wersję wykorzystywanej biblioteki podbijamy samodzielnie i świadomie, to działanie zewnętrznego systemu może się zmienić bez naszej wiedzy. I testy nas o tym poinformują.
Tę rolę testów dość mocno rozszerzam w jednym z materiałów darmowego mailingu SmartTesting…
A właśnie! W tym miejscu bardzo serdecznie zapraszam Cię do inicjatywy SmartTesting, którą organizuję wraz z dwójką mega-speców w temacie testów (jednostkowych i nie tylko). Nasi Eksperci: Olga Maciaszek-Szarma i Marcin Grzejszczak – czekają na Ciebie na SmartTesting.pl!
![]()
Niezła bomba, co nie? A skoro już o bombach mowa to warto zahaczyć o kolejną funkcję testów.
Bonus: “time bomb”
Na koniec dywagacji o roli testów zostawiłem mały smaczek: testy jako TIME BOMB.
Ile razy zdarzyło Ci się natknąć na komentarz w stylu “tymczasowa implementacja, do zmiany po najbliższym wdrożeniu w maju 2013”? A mamy kilka lat później… i teraz każdy boi się dotknąć tego kawałka kodu.
No właśnie.
Taki komentarz możemy (a nawet powinniśmy!) zastąpić testem. Testem, który przypomni o konieczności wrócenia do kodu w odpowiednim czasie. Jak to zrealizować? Bardzo prosto: piszemy test, który już swoją nazwą komunikuje docelowe zamiary i upewniamy się, że on nie przechodzi. Czyli piszemy failing test. A następnie w pierwszej linijce testu sprawdzamy, czy minął ten magiczny czas “do następnego wdrożenia”. Jeśli DateTime.Current < “may 2013” to robimy “return”. A w przeciwnym wypadku: wchodzimy w logikę, która zaświeci nam testy na czerwono. Takiego znaku nie zignorujemy.
JAK PISAĆ TESTY
Wiemy już, PO CO pisać testy. Teraz zastanówmy się, JAK to robić.
Pamiętajmy jednak, że nie ma jednej niezawodnej recepty na “dobry test”, niezależnie od kontekstu. Nie ma cudów: praktyka i identyfikowanie własnych pomyłek są najlepszym nauczycielem.
Niemniej warto znać kilka uniwersalnych rekomendacji.
Po pierwsze: FIRST
Na dobry początek poślizgamy się po teorii. W każdej dziedzinie życia jesteśmy bombardowani bezsensownymi akronimami i nie inaczej jest w przypadku testów. Z tym że akurat te rekomendacje są zasadne.
Przyjrzyjmy się rekomendacjom FIRST:
Fast
Dobry test powinien być szybki, i to w dwóch kontekstach.
Po pierwsze: szybki do uruchomienia. Jeśli uruchomienie testów będzie zajmowało dużo czasu, to po prostu nie będziemy tego robić. Ani u siebie (lokalnie), ani na build serverze.
A po drugie: powinien być szybki do przeczytania i zrozumienia. Bez tego niestety tracimy BARDZO ważny aspekt wspomniany w poprzednich akapitach, czyli dokumentację i komunikację za pomocą testów. A szkoda.
Isolated
Test (jednostkowy) powinien być niezależny od środowiska. Od systemu plików. Bazy danych. Zewnętrznego systemu. Powinien odbywać się w ramach pojedynczego procesu, nad którym mamy całkowitą kontrolę.
O tym wspominaliśmy już wcześniej, pamiętasz?
W przeciwnym wypadku mamy do czynienia z testem integracyjnym. One też są spoko, jednak mają inne cele i kierują się innymi regułami.
Repeatable
Różne narzędzia, runnery, a także konfiguracje systemu mogą wpływać na sposób wykonania testów. A to może z kolei spowodować, że jeśli się nie postaramy, to nie będziemy mogli na nich polegać!
Wyobraź sobie sytuację, w której wynik wykonania testów jest na Twojej maszynie inny niż na build serverze. Albo wszystko działa, chyba że odpalimy testy chwilę przed północą. Albo 29 lutego. Albo na kompletnie nowej, czystej wirtualce. Albo w losowej kolejności.
W takich wypadkach zaufanie do testów spada. A od tego momentu już jest niedaleko do tragicznego wniosku, że “to jednak nie działa, strata czasu, testy jednostkowe są fe”.
Self-verifying
Każdy test powinien jasno określać, CO testuje: czyli zawierać tzw. asercję.
Jeśli test automatycznie nie pokazuje błędu w przypadku niespełnionych założeń, to coś jest bardzo nie tak. Niestety nieraz widziałem testy bez asercji, których jedynym zadaniem było po prostu wykonanie kodu bez jawnie zdefiniowanego założenia. Nawet jeśli celem testu jest upewnienie się, że wykonany kod nie rzuci wyjątku – też powinniśmy zrobić na to asercję!
Do takiego stanu rzeczy może doprowadzić ślepy pościg za magicznym współczynnikiem code coverage w raportach wykonania testów. Ale do niego jeszcze dojdziemy.
Timely
Akronimy są czasami konstruowane na siłę. Pokuszę się o stwierdzenie, że autor “FIRST” koniecznie potrzebował wyrazu na “T”, żeby wszystko ładnie do siebie pasowało.
Ten ostatni czynnik można interpretować wielorako. Mi najbardziej podoba się wyjaśnienie, że testy powinny być napisane w odpowiednim momencie, czyli przed napisaniem testowanego kodu. Ten temat (nawiązanie do TDD) pojawia się już drugi raz w niniejszym tekście i już za chwilę go rozwiniemy.
Testy to też kod!
Do poprawnej implementacji przydatnych testów konieczne jest uświadomienie sobie, że testy to kod tak samo ważny, jak kod produkcyjny! Jeśli będziemy ten aspekt programowania traktować po macoszemu, to nie możemy potem narzekać na średnie efekty pracy.
Pokusiłbym się nawet o stwierdzenie, że czasami testy są WAŻNIEJSZE niż kod produkcyjny.
Jeśli DOBRE testy piszesz na trzeźwo, to kodzik możesz pisać nawet na haju ;) (don’t try this at home).

Szczególnie na początku przygody z testami bardzo trudno jest zaakceptować taki tok myślenia. A bo to przecież jakiś osobny projekt, który sobie krąży obok “właściwego” rozwiązania i nigdy nie jest nikomu dostarczany, nie wykonuje się w środowisku produkcyjnym, nie zarabia na siebie… Błąd! Do testów powinno się podchodzić z taką samą (lub nawet większą!) dbałością jak do każdego innego elementu systemu.
Warto wiedzieć, że kodu testującego będziemy mieli więcej niż kodu testowanego… Czy cokolwiek daje nam więc prawo chuchania i dmuchania na jeden kawał rozwiązania, podczas gdy drugi kawał to paskudne spaghetti tylko dlatego, że “klient go nie uruchomi“? Ano niekoniecznie.
Trzeba zastanawiać się nad strukturą testów. Planować hierarchię klas, stosować przemyślaną architekturę, poświęcać CZAS na podnoszenie ich jakości.
W wielu projektach testy składają się w 70-80% z kodu wytworzonego metodą kopiuj/wklej. A potem jest narzekanie, że testy spowalniają pracę. No heloł, co za niespodzianka!
Jeśli kod przygotowujący środowisko do testu się powtarza, to nie kopiujmy go w dziesiątkach testów, tylko zastosujmy odpowiednie mechanizmy pozwalające na jego reużycie.
Jeśli framework wykorzystywany do testów nie zawiera pożądanej funkcjonalności, to nauczmy się go rozszerzać.
Po prostu: zadbajmy o testy. Odwdzięczą się.
Niedopuszczalna jest sytuacja, w której raz napisany test żyje sobie własnym życiem od momentu zapalenia po raz pierwszy zielonej lampki w runnerze aż “do samego końca, mojego lub jej”.
W miarę uzupełniania testów nieustannie będziemy identyfikować scenariusze powtarzalne. Trzeba wtedy postarać się przeorganizować istniejące testy w taki sposób, aby proces dodawania kolejnych mógł skorzystać z już zawartej tam wiedzy i logiki. Są do tego sprawdzone taktyki, strategie, wzorce.
Na szczególną staranność i uwagę zasługuje proces definiowania kolejnych testów. Procedura ta musi być bardzo prosta, błyskawiczna i niewymagająca wielkiego wysiłku umysłowego. Jeżeli jednak natrafimy na trudność przy tym tworzeniu nowego testu, to oznacza, że trzeba w tym miejscu się zatrzymać. Niepewność “gdzie mam ten nowy test utworzyć” pokazuje, że w naszej hierarchii musimy zdefiniować nowe miejsce na dany typ testów. Nie wsadzajmy go gdziekolwiek, bo po kilku dniach takiego postępowania: burdel murowany.
Zawahanie: “Ale jak spreparować zależności dla tego nowego testu?”, wynika z nie do końca jeszcze gotowego procesu konfiguracji konkretnego kawałka kodu. Co robimy? Bynajmniej nie piszemy masy kodu konfiguracyjnego dla tego jednego nowego scenariusza! Zamiast tego szukamy innych testów powiązanych z tą częścią programu i analizujemy, czy nowy klocek nie pasuje przypadkiem do testów już utworzonych.
I tak dalej…
A to wszystko także po to, żeby lektura testów była nieskomplikowana. Testy powinno się czytać bez ciągłego zastanawiania: “A czemu tutaj tak, a nie inaczej…?“.
Jak nazywać testy
Nazwy testów są o tyle istotne, że oglądamy jest częściej niż nazwy innych metod. I to w sytuacjach wyrwanych z kontekstu IDE, np. w raportach z build servera albo powiadomieniach o nieprzechodzących testach. Dlatego też najbardziej liczy się czytelność pisanego kodu i łatwość powrotu do niego nawet po kilku miesiącach/latach od napisania. Fajnie by było, gdyby przyjęta konwencja ułatwiała nawigację w kodzie i pozwalała na szybkie zorientowanie się, jak działa dany komponent, bez wnikania w szczegóły implementacyjne. W idealnym przypadku raport z wykonania testów powinien być zrozumiały nawet dla nieprogramistów.
Złe przykłady nazw
Na początek uporajmy się z syfem, na jaki niestety często możemy się natknąć w różnych projektach. Przede wszystkim: nigdy nie powinniśmy nazywać testów w ten sposób:
- RegexParser_Parse_Test1
- RegexParser_Parse_Test2
- RegexParser_Parse_Test3
Takie nazwy NICZEGO nam nie mówią.
Więc jak?
Początek dobrych przykładów
Omówimy konkretny przykład metody generującej skróconą wersję dowolnego tekstu:
string Shorten (string input, int length);
Przy następujących założeniach:
- jeśli tekst nie jest dłuższy niż pożądana długość to, jest zwracany w całości;
- jeśli tekst jest dłuższy, to zwracany jest jego skrót o długości length-1 z końcówką w postaci znaku ellipsis (…).
Co musimy przetestować? Przede wszystkim:
- zwrócenie krótszego tekstu w całości;
- zwrócenie tekstu o żądanej długości w całości;
- zwrócenie dłuższego tekstu po operacji skrócenia.
(BONUS: Jakie jeszcze scenariusze powinniśmy przewidzieć? Zastanów się, mi przychodzą do głowy minimum dwa kolejne)
Pierwsza zasada nazywania testów, niezależnie od przyjętej konwencji:
Nazwa testu powinna opisywać działanie testowanego komponentu. W idealnym scenariuszu dowiemy się, jak ten komponent działa, bez czytania jego implementacji (lub implementacji testów).
Co za tym idzie: nazwy testów będą zdecydowanie dłuższe niż standardowe nazwy metod. I to jest OKej.
Najpopularniejsza konwencja nazewnicza
Najpopularniejszą konwencją nazewniczą dla testów jest taka propozycja:
NazwaTestowanejMetody_WhenTestowanyScenariusz_ShouldOczekiwanyRezultat
Jak zatem nazywałyby się nasze testy?
-
Shorten_WhenInputIsShorterThanRequiredLength_ShouldReturnWholeText
-
Shorten_WhenInputMatchesRequiredLength_ShouldReturnWholeText
-
Shorten_WhenInputIsLongerThanRequiredLenght_ShouldReturnShorterTextEndingWithDots
Można tak robić. I tak właśnie robiłem przez jakiś czas. Aż doszedłem do wniosku, że zdecydowanie widać tutaj pole do poprawy.
(Mała uwaga: ostatni z tych testów można rozbić na dwa – weryfikacja, czy tekst jest skrócony, i weryfikacja, czy kończy się kropkami.)
Pamiętajmy, że częściej będziemy czytać testy, niż je pisać. W związku z tym:
snake_case > camelCase
Notacja camelCase jest bardzo fajna, przydatna i przyjęta jako standard w wielu językach (np. Java czy C#). Jednak niezależnie od języka, na powyższym przykładzie widzimy jej negatywną cechę: nie sprawdza się przy dłuższych nazwach.
PascalCase czy camelCase sprawdzają się wyśmienicie dla nazw składających się z dwóch, trzech, maksymalnie czterech słów. Dłuższe ciągi są już trudne do przetrawienia dla “serca i umysłu”. Którą z tych linijek łatwiej przyswoić?
Porównajmy:
Shorten_WhenInputIsLongerThanRequiredLenght_ShouldReturnShorterTextEndingWithDots
vs
Shorten__When_input_is_longer_than_required_length__Should_return_shorter_text_ending_with_dots
Drugą wersję przynajmniej da się przeczytać (choć jeszcze można nad nią popracować).
Części wspólne nazw – po co?
Testy sprawdzają, jak działa kawałek logiki w systemie. Powinny – tak jak normalny kod – charakteryzować się wysoką kohezją (high cohesion). A więc w jednym kontenerze z testami (czyli zwykle: w jednej klasie testującej) powinniśmy grupować testy jednego kawałka kodu.
Jeśli mamy X testów zaczynających się od tej samej nazwy metody to możemy je po prostu umieścić w dedykowanej klasie. Zatem prefix z nazwą metody przenosimy z poziomu testu do poziomu klasy:
When_input_is_longer_than_required_length__Should_return_shorter_text_ending_with_dots
Dalej: jeśli każdy test zawiera słowo “should” to podczas czytania testów będziemy je automatycznie pomijać. Więc po co je w ogóle zawierać w nazwie? Zamiast tego napiszmy, jak dany komponent działa, a nie jak powinien działać.
When_input_is_longer_than_required_length__Returns_shorter_text_ending_with_dots
A co z kolejnością? Miejmy na uwadze CEL nazywania testów. Bardzo przydatna jest możliwość zrozumienia działania testowanego komponentu bez zagląda w jego kod (albo kod testów). W takim wypadku ważniejsze jest, CO dany komponent robi, niż KIEDY to robi.
Układa nam się fajne logiczne zdanie:
returns_shorter_text_ending_with_dots_when_input_is_longer_than_required_length
A nawet, jeśli zechcemy po prostu zrozumiale opisać ten scenariusz, bez żadnego copy/paste:
shortens_input_with_dots_when_its_too_long
Wystarczyło uwolnić się od sztucznie narzuconej konwencji i zaczęła nam się rodzić zwięzła, czytelna dokumentacja!
Zobaczmy, jak by wyglądał cały zestaw testów zaproponowany na początku tej części:
-
does_not_affect_short_input
-
does_not_affect_input_matching_required_length
-
shortens_input_with_dots_when_its_too_long
Rozumiemy, jak działa dany komponent, bez czytania kodu? Tak!
Oznacza to samo? Tak.
Bardziej czytelne? Tak.
Zrozumiałe dla nie-programisty? Tak!
Victory is ours!
W projektach testowych nie bójmy się łamiania konwencji z oficjalnych guidelines. Testy mają do odegrania ważne role i musimy im po prostu na to pozwolić.
Czy długość ma znaczenie?
A teraz, na koniec nazewniczych dywagacji, przykład naprawdę długiej nazwy testu (doskonale pełniącej funkcję dokumentacji):
fetches_attributes_values_for_objects__prevents_loading_empty_objects_with_ID_value_only_caused_by_incorrectly_setting_selection_range
I kolejny:
removes_duplicate_nodes_based_on_object_and_source_definition_before_persisting___fixed_problem_with_nodes_being_saved_more_than_once_after_refreshing_node_client_side
Jak widać, w tych testach podałem nie tylko oczekiwane zachowanie, ale również jego UZASADNIENIE. Owszem, można zamiast tego dodać zwykły komentarz. Ale o komentarzach pisaliśmy już wyżej. Poza tym dzięki takiej strategii informacja o przyczynie (być może dziwnego) działania zostanie zawarta w raportach z wykonania testów, co mocno pomaga.
Polemika?
Testami zajmuję się od lat. Napisałem na blogu masę artykułów, przeprowadziłem na ten temat wiele prezentacji i dziesiątki szkoleń. Wiem, jakie możesz mieć obiekcje do powyższych propozycji.
Nie za bardzo się to DLA Ciebie podoba? Podyskutujmy.
“Takie nazwy są niezgodne z naszymi standardami! One są niezgodne z jakimikolwiek standardami!”
Odpowiedź krótka: no to co? Standardy są po to, aby ułatwiać życie, a nie je utrudniać. Ogólne zasady, stworzone do zachowania spójności w kodzie produkcyjnym, nie mają tu zastosowania.
Główny powód jest bardzo prosty: testów nigdy nie wywołujemy w kodzie. Do testów nie potrzebujemy intellisense, więc ich nazwy mogą być długie. Nie muszą zaczynać się od wielkiej litery – nie “zabrudzi” to nam API.
Wiadomo, że zawsze metoda powinna w miarę dokładnie opisać zawarty w niej kod, ale dla testów tych informacji jest po prostu więcej niż w “zwykłym” kodzie.
“Po co szczegółowe nazwy? Od tego są komentarze!”
Tak jak wspominałem – komentarze mają irytującą tendencję do opisywania kodu, który BYŁ pod nimi w momencie ich pisania, a nie tego, który znajduje się tam aktualnie.
Oczywiście nazwa testu to też tylko kawałek tekstu, tak samo jak komentarz, jednak sposób pracy z testami jest nieco inny niż z normalnymi metodami. Jeśli działanie testowanej metody ma się zmienić, to zwykle po prostu kasujemy test i piszemy nowy, zachowując synchronizację nazwy z faktyczną implementacją.
Dodatkowo komentarze są niezwykle podatne na “nieumyślne” mnożenie się metodą kopiuj/wklej wraz z komentowanym kodem, który zaraz po wklejeniu jest poddawany obróbce.
“Jeśli test się zepsuje, to i tak od razu trzeba pójść do kodu i go naprawić, a wtedy już będzie wiadomo, co on robi.”
Rola testów nie powinna ograniczać się do zapalania zielonych i czerwonych lampek (choć niestety zgadzam się, że często tak jest; między innymi dlatego pracujemy nad SmartTesting).
Testy mogą służyć jako doskonała dokumentacja testowanego kodu i odpowiednie ich nazwanie może w tym znacząco pomóc. Dobrze nazwane testy umożliwią zerknięcie na raport z ich wykonania i na podstawie samego takiego raportu, bez wnikania w jakąkolwiek implementację, wywnioskowanie, jakie jest zachowanie testowanej klasy czy nawet całego komponentu.
Testów nie czyta się tylko wtedy, gdy “przestają działać”. One mogą być idealnym miejscem do rozpoczęcia zapoznawania się z kodem (zarówno dla nowego w projekcie programisty, jak i dla samego autora po upływie kilku miesięcy).
“Ale narzędzie generuje mi takie nazwy testów!”
(Ten argument pozostawimy bez komentarza :) )
Jak konstruować testy? AAA to the rescue
Dobry test da się podzielić na trzy etapy:
Przygotowanie (Arrange)
W tej fazie tworzymy testowany obiekt, przygotowujemy dla niego środowisko i definiujemy zmienne.
Zwykle każdy test ma inny etap Arrange (bo w końcu każdy test testuje inny scenariusz).
Wykonanie (Act)
Wykonujemy testowaną logikę. Zwykle powinna to być jedna linijka. Testy zgrupowane w jednym kontenerze (klasie testującej) mają zazwyczaj identyczną fazę Act.
Weryfikacja (Assert)
Pisałem wyżej, że każdy test powinien zawierać asercję, czyli jawną weryfikację pewnego założenia.
Sprawdzamy, czy poprzednia faza wywołuje oczekiwane konsekwencje (albo nie wywołuje nieoczekiwanych).
Dobry test ma zwykle jedną (logiczną) asercję.
Na początku nauki możesz nawet pokusić się o wstawienie do pustego testu komentarzy dzielących go na te trzy fazy, by dopilnować, że na pewno nie mieszasz ich ze sobą.
Bonus: testy testów?
Decyduję się w tym miejscu na kontrowersyjną wrzutkę, a co tam ;).
Niejednokrotnie pisałem nietrywialny kod pomocniczy, dedykowany testom. Jak? Tak jak przy pisaniu normalnego kodu: stosując TDD!
Może to brzmi przesadnie, ale nie ma w tym nic dziwnego. Skoro testy traktujemy jak normalny kod, to czasami uzasadnione jest nawet na tym poziomie programowanie sterowane testami.
KIEDY PISAĆ TESTY
Moment pisania testów jest nierzadko kluczowy dla zmaksymalizowania efektywności całej procedury. Pamiętamy “T” (czyli Timely) z akronimu FIRST, co nie?
Możemy wyróżnić kilka najważniejszych etapów tworzenia oprogramowania, które z reguły są odpowiednią chwilą na napisanie testu. Ale tak naprawdę wszystko staje się prostsze, gdy zaakceptujemy, że:
Pisanie testów do istniejącego kodu jest jak gra wstępna po seksie.

Testy mają bardzo wiele zalet i służą więcej niż jednemu celowi. Wykorzystanie w pełni ich potencjału jest możliwe tylko wówczas, gdy napiszemy je PRZED testowanym kodem.
Test-first
Oczywisty pierwszy punkt w temacie “kiedy pisać testy?” brzmi: “przed napisaniem właściwego kodu“. DOH!
W praktyce, na co dzień, to jest TA droga. Musimy oczywiście zapłacić frycowe, jednak przy odpowiedniej edukacji nie jest ono strasznie kłopotliwe. A po drugiej stronie czeka na nas oszczędność czasu (sic!) i… po prostu przyjemność. Bez kitu.
Jednak czy zawsze chodzi wyłącznie o pojawiające się już wyżej TDD, czyli Test Driven Development? Niekoniecznie.
Test-first to niekoniecznie TDD!
Zaraz podywagujemy nad różnicami, jednak wywodzący się z TDD cykl pozostaje niezmienny:
red → green → refactor
napisz niedziałający test → napisz najprostszy kod spełniający założenia testu → podnieś jakość kodu bez modyfikacji logiki (czyli bez psucia testów)
Pamiętamy przy tym, że ten ostatni niebieski element – refactor – jest pełnoprawnym członkiem rodziny.
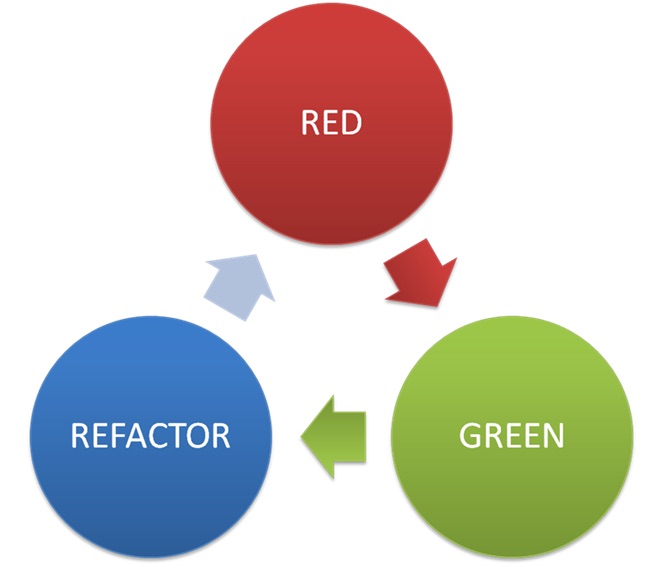
Nie zaniedbujemy refactoringu! Żeby za jakiś czas nie płakać nad słabym kodzikiem i nie żebrać o refactoring sprint (który krytykowałem w jakże wymownie zatytułowanym tekście Refactoring sprint? Plażo, please…).
Ale wróćmy do dwóch sposobów pisania testów przed kodem produkcyjnym:
TDD vs test-first
Podejście pierwsze to takie “prawdziwe” TDD, jak promuje je Uncle Bob Martin czy Kent Beck. Polega na tym, że piszemy testy tylko przez chwilę: do momentu, gdy kod przestaje nam się kompilować. Albo gdy test nie przechodzi. Wtedy przeskakujemy do kodu produkcyjnego i klepiemy… przez kolejną chwilę. Do czasu, aż kod zaczyna się kompilować i wszystkie testy przechodzą.
Takie przeskakiwanie między kontekstami wymaga bardzo dużo dyscypliny i treningu. Szczególnie początkującym na pewno sprawi to sporo trudności. Pełny cykl “test → kod” zajmuje często mniej niż minutę.
Warto się nauczyć i popraktykować TDD, jednak…
Jednak bardziej praktyczne jest luźniejsze podejście nazwane Test-First Approach. Sprowadza się ono do prostej zasady: piszemy testy do kodu, którego jeszcze nie mamy. Tylko tyle i aż tyle. Często warto stworzyć na początek wiele testów zanim zabierzemy się do kodu, który je zazieleni.. Ba, czasami nawet można skupić się na pisaniu PUSTYCH testów! A ich nazwy pozwolą zweryfikować, czy na daną chwilę spisaliśmy w “kompilowalnej” postaci wszystkie wychwycone wymagania, scenariusze, wartości brzegowe. Upewniamy się w ten sposób, że niczego nie pominęliśmy i niczego nie brakuje. To właśnie ten – wspomniany na początku tekstu – sprawdzian specyfikacji. Pamiętasz?
I dopiero mając baterię czerwonych testów, zabieramy się do faktycznej implementacji wymagań.
Tak czy siak, zawsze pamiętamy o rewelacyjnym pytaniu:
Would you rather test-first or debug-later?
Uncle Bob Martin

I, po udzieleniu jedynej słusznej odpowiedzi ;), lecimy dalej.
Jak zmusić się do pisania testów przed napisaniem kodu?
Wiem, jak ciężko jest zmienić swój sposób kodowania i przestawić się na podejście test-first. W końcu przyzwyczajenie, pielęgnowane od lat, nie umrze tak łatwo. Napiszę linijkę czy dwie, wcisnę F5, kliknę w aplikacji w odpowiedni guzik i tym samym WIEM, ŻE DZIAŁA. Po co mi tutaj testy?
Zachęcam do przeprowadzenia prostego eksperymentu. U mnie zaproponowana zmiana wpłynęła na wszystko – całe moje podejście do programowania. Na szczęście sposób ten odkryłem stosunkowo wcześnie.
Eksperyment polega na jednym banalnym kroku:
Pisz kod, którego nie da się uruchomić!…
…bez wykonania testów.
Nie pisz kodu w projektach aplikacyjnych. Programista uczący się testowania zapomina o Main(), exe czy webapp. To zwykłe non-runnable biblioteki są miejscem, w którym rośnie kodzik z logiką.
Faktyczna APLIKACJA to tylko sposób na zaprezentowanie kodu użytkownikom.
W momencie, w którym uwolnisz się od exeków, odkryjesz śmieszną prawdę: nie jesteś Linusem Torvaldsem. Nie jesteś w stanie zaufać sobie na tyle, aby taki kod pchnąć do repozytorium, dostarczyć do finalnego rozwiązania. Nie możesz go uruchomić, więc jak sprawdzić, że działa? Ano właśnie: pozostają Ci tylko testy!
Skoro Twój kod może być wykonany wyłącznie w kontekście testów jednostkowych, to zaczniesz przykładać do nich wagę. Kolejne linijki będą MUSIAŁY być napisane tak, aby testy w łatwy sposób się do nich dobrały. Wtedy przekonasz się na własnej skórze, że życie jest o wiele prostsze, jeśli najpierw piszesz testy. I to będzie pierwszy krok.
Ale ten temat to dość luksusowe okoliczności. Pisanie nowego kodu jest takie fajne między innymi właśnie dlatego, że możemy najpierw napisać do niego testy.
A co z przeciwną sytuacją?
Jak wprowadzać testy do istniejącego systemu?
Jeśli już masz swoją Michę Pełną Spaghetti, to do problemu możesz podejść na kilka sposobów. Jeden z nich jest bezsensowny. A pozostałe: działają spoko.
Sposób bezsensowny: AAAAAATTTAAAACKK!!!!
Rzucanie się na hura i dopisywanie testów tylko po to, żeby mieć testy, to złe rozwiązanie, choć nierzadko spotykane.
Pracowałem kiedyś przy dużym projekcie w kilkunastoosobowym zespole. Kod już wtedy był dość wiekowy i niejedna łza kapnęła na klawiaturę podczas prób poprawienia jego jakości. Jak można ulepszyć kod, który nie ma testów? Hmm… dopisać do niego testy, co nie?
Niby logiczne. Ale nie do końca.
Ówczesna próba poradzenia sobie z problemem wyglądała tak: bierzemy na wakacje stażystów i oni dorobią testy do systemu! Ile można naklepać testów przez dwa miesiące? Całą masę! No to doklepali.
Po czym skończyli praktyki. A my te testy skasowaliśmy. Bo się do niczego nie nadawały. Bummer. I to nie była wina praktykantów!
Testowanie istniejącego kodu “na siłę” jest bez sensu.
Mając działający, zarabiający kod, nie rzucajmy nagle wszystkiego, by zacząć go “otestowywać” tylko dlatego, że “ktoś powiedział że testy poprawiają jakość kodu”. Mam nadzieję, że to jest już jasne.
Nie da się dopisać dobrych testów, nie ingerując inwazyjnie we flaki systemu. Taki kod w swojej oryginalnej postaci prawie na pewno do testowania się po prostu nie nadaje. Szkoda na to czasu, szkoda ludzi. A korzyści będą raczej minimalne, albo nie będzie ich wcale.
Takie podejście jest stosowane ze złych pobudek:
Code coverage
Ta nazwa pojawiła się już wyżej, w akapicie o self-verifying tests, pamiętasz? Metryka niniejsza wskazuje, ile % linijek kodu jest wykonywanych w kontekście testów i szczerze mówiąc: niesie to raczej niewiele informacji. Szczególnie w dużych, nieotestowanych systemach nie ma sensu dążyć do wysokich wartości tego współczynnika w krótkim czasie. Podążanie za radą “cały kod trzeba pokryć testami” może wydawać się sensowne, ale niezrozumienie implikacji doprowadzi do problemów.
Metryka code coverage może przyjąć dwie istotne wartości:
0% oznacza, że testujesz za mało. 100% oznacza, że testujesz za dużo.

Nie zawracajmy sobie głowy pokryciem kodu na tym etapie.
Kiedy zatem pisać testy w istniejącym systemie?
Nowy kod
Powtórzę jak mantrę: przed napisaniem kodu produkcyjnego! Przecież do istniejących systemów też dopisuje się nowe rzeczy, prawda? A wtedy: opisywane wyżej test-first approach.
Wystarczy uświadomić sobie, że każda (nawet malutka) nowość, może być tworzona w oderwaniu od pełnego wyzwań kodu legacy. Piszmy małe komponenty, definiujące swoje parametry wejściowe oraz wartości zwracane. Niech one się komunikują z tym wielkim, złym, strasznym starym systemem za pomocą adapterów. Na przykład poprzez praktykę tworzenia tzw. mikrokontraktów, o której pisałem tutaj. I każdy taki mikrokontrakt kodujemy tak, jak nam się podoba, więc z testami na pierwszym miejscu.
Proste!
Bugi
Drugi scenariusz dopisywania testów do istniejącego systemu to kontekst poprawiania błędów. Bo błędy są przecież zgłaszane.
Przed naprawieniem błędu udowadniamy testem, że błąd faktycznie występuje. Najpierw piszemy “czerwony” failing test, modelujący poprawne zachowanie, a dopiero potem kod, dzięki któremu test się zieleni, czyli faktyczny bugfix. Bardzo podoba mi się nawet praktyka wrzucania takich testów i poprawek do osobnych commitów (o czym rozwodziłem się chociażby w tym obszernym tekście o kontroli wersji):
red → commit → green → commit → refactor → commit
Owszem, może to wymagać trochę czasu i refactoringu w poprawianym obszarze, ale przecież i tak będziemy ten kod zmieniać. Natomiast testy w tym kontekście aż kipią od korzyści.
Po pierwsze: wiemy, że naprawdę coś jest źle. Po drugie: wiemy dokładnie, CO jest źle. Po trzecie: mamy punkt startowy do naprawiania buga. Po czwarte: mamy zabezpieczenie, że ten sam bug nie wystąpi w przyszłości (bo wtedy owe testy nam się wywrócą). Więc wracamy do opisywanej na początku tekstu jednej z ról testów: siatka bezpieczeństwa przed błędami regresji. Po piąte: skupiamy się na istocie problemu, dzięki czemu mamy potencjalnie spore szanse na zidentyfikowanie dodatkowych warunków, w których z danym kawałkiem kodu coś może być nie tak. Po szóste – tworzymy archiwum i dokumentację błędu oraz jego rozwiązania na przyszłość.
I tak dalej.
Refactoring
Temat zasadności poświęcania czasu wyłącznie “na refactoring” już poruszyliśmy. Ale jest jak jest: założymy, że zespoły są skłonne negocjować godziny, dni czy nawet całe sprinty na “poprawę kodu”, bez dodawania nowych funkcji i bez fixowania błędów. W każdym systemie raz na jakiś czas zdarza się, że ktoś w końcu nie wytrzymuje i rozlega się krzyk: “Nie no k… nie dam już rady, musimy z tym kodem coś zrobić!“. I w tym momencie mogą się nam zaświecić oczka. Tak, to jest właśnie czas na zaproponowanie zespołowi czy managerowi: “To może zobaczymy, z czym się te testy je…?“.
Na czym polega refactoring? Na zmianie struktury kodu, bez modyfikowania jego zachowania. Ten kodzik – jak ustaliliśmy już wcześniej – żyje i na siebie zarabia. Nieładnie z naszej strony byłoby niechcący zmienić jego działanie. Ale jak się upewnić, że faktycznie niczego po drodze nie zepsujemy? Czyli: nie wprowadzimy błędów regresji.
Oczywiście: odpowiednia siatka bezpieczeństwa, utkana z testów do dobrze wyselekcjonowanego obszaru kodu, nas przed nimi uchroni! W testach modelujemy aktualne zachowanie pewnej logiki i dzięki temu gwarantujemy, że refactoring niczego nie zmieni. Taki proces może być dość czasochłonny, ale efekty w większości przypadków będą tego warte. Już same próby pokrycia testami starego molocha, Potwora Spaghetti, wymuszą bardzo dokładną analizę działania utrzymywanego kodu. Mało tego, prawie na pewno nie obejdzie się bez zmian w designie tylko po to, aby testy w ogóle umożliwić. I bardzo dobrze – o to chodzi!
Po pokryciu kodu baterią testów znajdujemy się na etapie “green” z TDD. Czas na “refactor” – reorganizację, upiększanie i dodatkowe pokrywanie testami kodu, tak aby praca z nim była w przyszłości czystą przyjemnością. Dodawać chyba nie muszę, że dzięki temu w tym naszym małym wycinku właśnie utworzyliśmy test-enabled-area gotowe do bezbolesnego utrzymania zgodnie z zasadami test-first.
Niespiesznie, powoli, jak żółw ociężale…
Jeden teścik tu, jeden tam.
Czas płynie.
System ewoluuje.
Zespół się uczy.
A dzięki tym praktykom jakość kodu zacznie stale wzrastać:
- testujemy przed napisaniem nowego kodu;
- testujemy przed poprawieniem buga;
- testujemy przed refactoringiem.
To działa, choć trochę potrwa, ale:
Nie da się wieloletnich zaniedbań naprawić – ot tak – w tydzień czy miesiąc.
Pamiętajmy, że pośpiech upokarza ;).
BONUS: WYMÓWKI
Dlaczego nie piszesz testów?
Pewnie dlatego, że Ci się nie chce. Albo nie umiesz. Albo nie masz czasu. Albo w Twoim systemie “się nie da”. Albo szef nie pozwala. Albo testy “nie działają”.
Albo – moje ulubione – “nie za to mi płacą”!
Brzmi znajomo?
W takim razie tym bardziej KONIECZNIE dołącz do SmartTesting.pl i naucz się razem z nami jak to robić porządnie i jak wynieść z tego maksimum korzyści!
![]()
BONUS 2: TESTY KONWENCJI
A na koniec jeszcze bonusowe video. Jednej – wspaniałej! – roli testów nie poruszyliśmy w tym artykule. A tzw. testy konwencji to absolutnie rewelacyjne narzędzie do …
Zresztą zobacz:
(tym filmem rozpoczynamy przygodę z mailingiem SmartTesting)
CZUBEK GÓRY
Niniejszy tekst powstawał bardzo długo. Biłem się z myślami, co tutaj zawrzeć, a co pominąć. Nie chciałem robić z tego książki :).
Miej na uwadze, że cała zawarta tu wiedza to pewien kompromis. To tylko liźnięcie tematu.
O WIELE więcej znajdziesz na smarttesting.pl, gdzie Cię serdecznie zapraszam.
W tej chwili to najlepszy krok, jaki możesz zrobić dla swojego programistycznego rozwoju. Czekamy na Ciebie!
PROŚBA NA KONIEC
Jeśli uważasz ten tekst za wartościowy, to bardzo Cię proszę: podziel się nim w internecie!
Opublikuj go na Twitterze, Instagramie czy Facebooku. Udzielasz się na tematycznej programistycznej grupie? Podrzuć tam link. Jesteś częścią programistycznego forum? Daj znać innym forumowiczom. Po prostu skopiuj link i opublikuj z kilkoma słowami swojego komentarza.
Niech się niesie dobre słowo. Testy FTW!



