A cóż to i dlaczegóż to
Niedawno Szymon napisał posta o O/R Mapperach. Korzystając z impulsu postanowiłem także popełnić co nieco w tym temacie, tym bardziej że tą konkretną notkę zaplanowałem przynajmniej 2 miesiące temu. Może ona być uzupełnieniem dla projektów wspomnianych przez Szymona, czyli NHibernate, Linq2Sql i Entity Framework.
Słowem wprowadzenia…
LLBLGen Pro to płatny O/R Mapper od firmy Solutions Design. Najważniejszym człowiekiem za nim stojącym jest Frans Bouma – na to nazwisko natykałem się w internecie jeszcze przed moim kontaktem z LLBLGen.
“Hola hola, płacić za O/R Mapper??” – wykrzyknąć ktoś może w niezmiernym zdumieniu. No i fakt, cena narzędzia (249 jełro) może być dla “samodzielnych” programistów nieco odstraszająca. Warto jednak pamiętać o tym, że fakt “darmowości” bądź “OpenSourcowości” jakiegoś produktu w wielu firmach automatycznie go dyskwalifikuje. W takich sytuacjach programistów w nich pracujących można podzielić na cztery grupy pod względem implementacji dostępu do danych:
1) ręczne pisanie procedur / zapytań… wszyscy byliśmy w tym miejscu i każdy się chyba zgodzi, że nie jest to wymarzony sposób na pracę z danymi, nawet jeśli większość kodu sobie wygenerujemy jakimś pisanym domowymi sposobami generatorem
2) wykorzystanie propozycji z Redmond, czyli Linq2Sql (który jest technologią umierającą), Entity Framework (o którym można przeczytać wiele, z czego póki co 90% to narzekania i wytykanie błędnych rozwiązań; co się pewnie trochę zmieni po wypuszczeniu kolejnej wersji) czy DataSety (o których pisać nawet nie będę, bo traktowanie ich jako technologii dostępu do bazy danych w “normalnej aplikacji” to trochę naciągane rozumowanie)
3) pisanie “własnego O/R Mappera” – tworzyłem kiedyś w pracy coś takiego i nawet zgrabnie tłumaczyło zapytania obiektowe do postaci SQL; dla mnie osobiście to zadanie się podobało, ponieważ było fajnym wyzwaniem architektoniczno-programistycznym; patrząc jednak z punktu widzenia pracodawcy (który chyba sobie z tego do końca sprawy nie zdawał), to pieniądze wydane na pensje pracowników biorących udział w tworzeniu tego projektu (bo nie robiłem wszystkiego tylko i wyłącznie sam) można było wydać na licencje chociażby takiego LLBLGen dla całego działu dev i wyszłoby się na plus: kasy by jeszcze zostało, a firma miałaby gotowy do użycia, przetestowany przez setki klientów, niewymagający ciągłych modyfikacji, supportowany na zewnątrz, dopieszczony produkt, oferujący 100x więcej funkcjonalności niż to co udało mi się wypracować
4) kupno narzędzia, za którego poprawne działanie, poprzez pobranie opłaty za licencję, odpowiedzialna jest firma zewnętrzna
Nie wiem czy się zgodzicie (podejrzewam że tak), ale wg mnie rozwiązanie 4) jest rozwiązaniem najlepszym. Zobaczmy zatem co oferuje nam najbardziej znany produkt z kategorii “płatnych ORM dla .NET”. Dobrze jest wiedzieć, że coś takiego istnieje, a z moich obserwacji wynika że w Polsce stosunkowo niewiele osób o nim słyszało.
Cały poniższy tekst nie ma być tutorialem “jak zrobić sobie aplikację z LLBLGen” – od tego jest (całkiem dobra i dość wyczerpująca zresztą) dokumentacja. Nie ma być też dokładnym omówieniem założeń produktu (te z kolei znajdziemy w sekcji “Concepts” wspomnianej dokumentacji). Ma być raczej zbiorem przykładów, uwag i spostrzeżeń, które rzuciły mi sie w oczy podczas dwumiesięcznej pracy z LLBLGen na podstawowym poziomie “pobierz/dodaj/zaktualizuj/usuń”. Po lekturze czytelnik powinien być w stanie ocenić czy w ogóle mógłby w przyszłości rozważyć zastosowanie takiego rozwiązania.
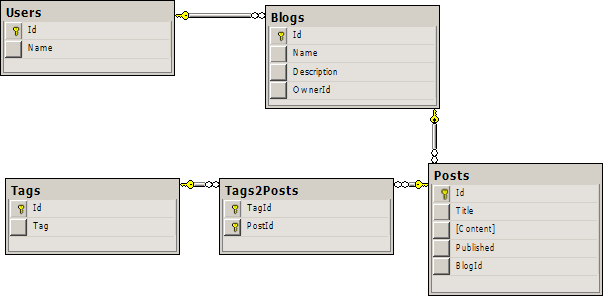
Przykłady oparte będą na bardzo prostej bazie danych: użytkownik ma blogi, blog ma posty, a posty są połączone relacją wiele do wielu z tagami:
Kod C# wygenerujemy przy pomocy narzędzia pozwalającego na wizualną konfigurację tego procesu:
1) tworzymy nowy projekt LLBLGen:
2) wskazujemy źródłową bazę danych
3) wybieramy tabele do wygenerowania (LLBLGen oferuje dwa tryby generacji kodu: Adapter i Self Servicing; jedyny z którego korzystałem to Adapter, ponieważ Self Servicing jest implementacją wzorca Active Record, który to wzorzec nadaje się moim zdaniem jedynie do mikro-projektów)
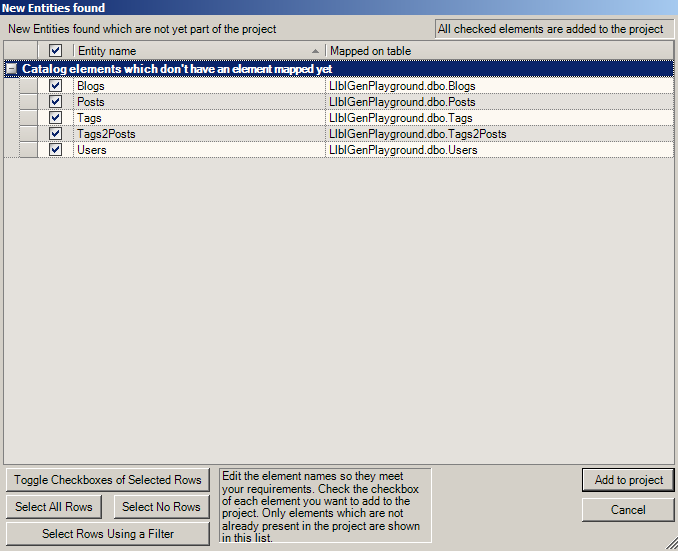
4) efekt to rozpoznane kolumny, ich typy, relacje pomiędzy tabelami itd. – nic szczególnie interesującego; na tym etapie możemy zmodyfikować nazwy klas do wygenerowania (np. liczba mnoga na pojedynczą), kolumn, poukrywać niepożądane kolumny etc.:
5) na koniec wciskamy F7, podajemy katalog docelowy dla wygenerowanych projektów Visual Studio i wsio, generację mamy za sobą, możemy zacząć operować na naszej bazie danych
Zaczniemy od zniechęcania, czyli…
Wady
1) “rozdęte” klasy
Tak, to prawda. Zapomnij o POCO.
Przygotuj się na pisanie mapowań wygenerowanych klas na domenę, ponieważ to co otrzymujesz z generatora nie nadaje się na “obiekt biznesowy”… a już na pewno nie na transport w środowisku rozproszonym! Ale z drugiej strony jakiekolwiek generowanie klas na podstawie bazy danych w celu zawarcia w nich mechanizmów pozwalających na proste zarządzanie kontaktem z bazą kończy się w ten sposób, więc nie jest to żadne zaskoczenie. Przy Linq2Sql czy Entity Framework mamy to samo.
2) momentami skomplikowane zapytania
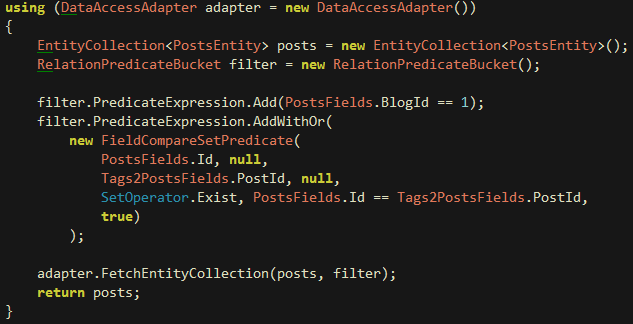
Półtorej godziny spędziłem kiedyś nad sformułowaniem za pomocą obiektów LLBLGen zapytania, które można przetłumaczyć na nasz przykład jako “pobierz mi posty z bloga o ID = 1 lub takie które nie mają tagów” (bezsens takiego zapytania w aktualnym scenariuszu pomińmy milczeniem). Teraz zajęłoby mi to chwilę, ale momentami można natrafić na banalny z pozoru problem, który zmusi nas do przewertowania dokumentacji, przeszukania forum i eksperymentowania przez bliżej nieokreśloną ilość czasu. Na szczęście nie są to częste przypadki. Dla zainteresowanych, problem ten rozwiązuje średnio opisany w dokumentacji FieldCompareSetPredicate:
3) “eksplorowalność”: minus jeden
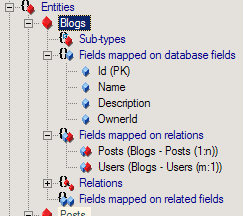
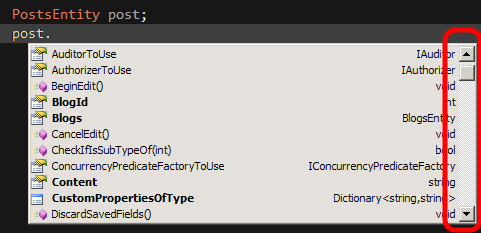
Korzystając z LLBLGen musimy przyzwyczaić się do ciągłego odwoływania się do typów wyliczalnych (enumów), klas statycznych, zgadywania “co też robi z tym obiektem przeciążany operator?” itd. Można się do tego dość szybko przyzwyczaić, jednak na początku odnosi się wrażenie, że można było całość ładniej… zaprojektować. Oto przykładowy kod pobierający bloga o zadanym ID wraz z przypisanymi do niego postami:
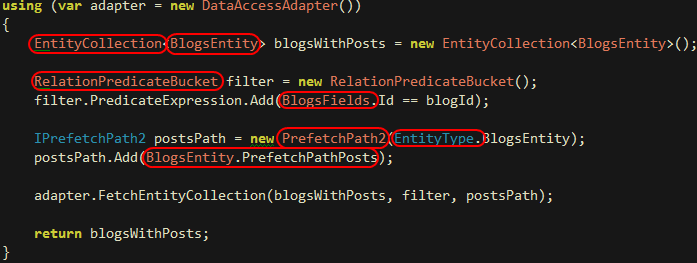
Na czerwono zaznaczyłem klasy i właściwości, o których istnieniu musimy wiedzieć, zanim uda się nam coś osiągnąć. Jest tego sporo i nie odkrywa się tego zbyt intuicyjne, niestety na początku bez otwartej nieustannie dokumentacji ciężko jest zrobić co_kol_wiek. Wystarczyłoby podczas generacji utworzyć jeden centralny punkt dla każdego Entity zbierający właściwości/klasy umożliwiające wykonanie wszystkich operacji, dobrze to opisać, i świat byłby lepszy.
Czas przyjrzeć się produktowi z drugiej strony:
Zalety / uwagi
1) Wzrost wydajności programisty od pierwszych chwil
To co widzieliśmy na początku artykułu – zaznaczenie checkboxów przy odpowiednich tabelach – jest wszystkim, co musi umieć programista aby rozpocząć pracę. Tak naprawdę może rozpocząć ją więc natychmiast. Dodanie LLBLGen do projektu nie wiąże się z dużym kosztem “edukacyjnym”. Jest to po prostu warstwa tłumacząca zapytania do obiektów na SQL, i tyle. Nie trzeba przejmować się nauką polityki cache stosowanego w LLBLGen, ponieważ takiego cache po prostu nie ma. Nie trzeba zastanawiać się nad mapowaniem kolumn na właściwości – robi się to samo. Oczywiście przez takie podejście możemy stracić możliwość uszycia sobie warstwy DAL idealnie dopasowanej do naszej aplikacji, ale wielokrotnie nie jest to niezbędne (poza tym do LLBLGen można się oczywiście w wielu miejscach “podpiąć” własnym pluginem i dostosować jego działanie do własnych wysublimowanych potrzeb, ale tego nie robiłem). Na podaną w wadach konieczność orientowania się w wewnętrznych klasach lekiem są przykłady, przykłady i jeszcze raz przykłady. Wystarczy że jedna osoba w zespole poświęci pół dnia na dokładne zapoznanie się z tymi mechanizmami i już od dnia następnego będzie w stanie pomóc reszcie stworzyć większość zapytań.
Przykłady pojawiające się w tym poście, jak i te zawarte w dokumentacji, aż kłują w oczy możliwością utworzenia jakiegoś helpera redukującego liczbę linii kodu.
2) Pobieranie wybranych kolumn
Wielokrotnie podczas rozmów o OR Mapperach jako argument przeciwko nim słyszałem takie coś: “po co mi ściągać cały wiersz z tabeli, jeśli potrzebuję tylko jedną czy dwie kolumny? a nie będę przecież na każdy osobny taki przypadek tworzył kolejnej klasy, kolejnego mapowania”. No i co racja to racja, dlatego poniżej przykład pobrania wszystkich postów, jednak pobrane obiekty zawierać będą jedynie ID i tytuł:
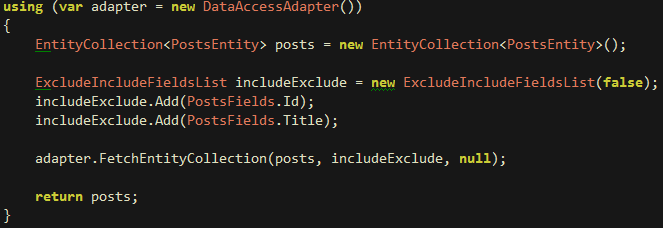
3) Dokumentacja, support
Płatny produkt powinien mieć godną dokumentację i wsparcie producenta. Tak jest w tym przypadku, w dołączonych plikach można znaleźć naprawdę ogrom informacji. Dodatkowo na forum również znajduje się masa rozwiązanych problemów. No i oczywiście jeżeli nie znajdziesz odpowiedzi na dręczące cię pytanie, masz pełne prawo oczekiwać, że ktoś z zespołu odpowie ci tak szybko jak to możliwe.
4) CommandLine – błyskawiczne odzwierciedlanie w kodzie zmian z bazy
Narzędzie CliGenerator.exe pozwala na automatyzację całego procesu generacji kodu. Dlatego też dobrą praktyką byłoby przechowywanie w repozytorium samego pliku projektu LLBLGen, a generacja kodu następowałaby na maszynie programisty bądź na build serverze.
5) Wsparcie dla LINQ
W najnowszej wersji softu wprowadzono możliwość pisania zapytań LINQ i przekazywania ich do infrastruktury LLBLGen. W dokumentacji wygląda to przyjemnie, ale nie korzystałem z tego udogodnienia. Wcześniej alternatywą (wcale nie taką złą) dla LINQ było przekazywanie obiektów klasy RelationPredicateBucket z zawartymi kryteriami wyszukiwania.
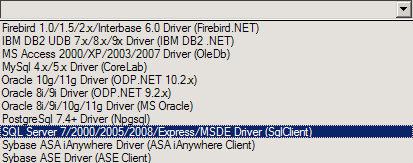
6) Wsparcie dla wieeeelu baz danych
Nie powinno to specjalnie dziwić, ale LLBLGen oferuje wsparcie dla wielu silników baz danych. Niechaj poniższy screen pokaże co i jak:
Czy warto?
Celem tego posta nie była reklama czy dokładna prezentacja LLBLGen – tak naprawdę liznęliśmy tylko wierzchołek góry lodowej (ależ dwuznaczne!!). Chciałem tylko pokazać, że poza światem open source istnieją takie PRODUKTY, i wcale nie muszą one pochodzić z firmy Microsoft.
A odpowiedź na pytanie “czy warto?” jest bardzo prosta:
Jeżeli możesz korzystać z rozwiązań darmowych (NHibernate, Active Record z Castle Project, SubSonic…) – go for it, Luke!
Jeżeli nie możesz korzystać z rozwiązań darmowych bądź zależy ci na zrzuceniu części odpowiedzialności za powodzenie twojego projektu na kogoś innego, oczekując supportu z prawdziwego zdarzenia i “pochylania się” nad każdym twoim problemem – LLBLGen Pro jest rozwiązaniem na dzień dzisiejszy po prostu najlepszym. A jeśli twoja firma zapiera się, że jest kryzys i nie stać jej na nowe inwestycje, postaraj się przemówić im do rozsądku. Przerzucenie się na coś takiego jest naprawdę rozwiązaniem win-win, gdzie oni są szczęśliwi (zarabiają na licencjach) a korzysta również twoja firma (pieniądze wydane na licencje z pewnością zwrócą się bardzo szybko, bo tak errorogenne:) i nieprzyjemne pisanie kodu dotykającego bazy danych zostaje z prac nad projektami całkowicie usunięte). Ściągnij trial i zobacz sam. Ściągnij specjalnie przygotowane materiały i pokaż managerowi. Po prostu: zrób wszystko, aby nie tracić życia na ręczne pisanie banalnego, powtarzalnego SQLa!
Powodzenia.







Bardzo fajny tutorial. Nie zdawałem sobie sprawy z istnienia czegoś takiego:) To rzeczywiście czasem jest duży problem z tym open-source: w mojej firmie spotkaliśmy się z projektem, w którym klient miał listę bibliotek o-s, których nie życzy sobie używać…
W temacie płatnych O\RM-ów – jest coś takiego: http://www.telerik.com/products/orm.aspx. Ma ktoś jakieś doświadczenia z tym produktem?
@simon:
Początki LLBLGen sięgają roku 2002, kiedy Frans Bouma stworzył darmowy projekcik generujący DAL. Potem przekształciło się to w kombajn ORM. 7 lat na rynku to kaaawał czasu, tym bardziej jeśli firma jest skoncentrowana na tym jednym produkcie.
Telerik z kolei może rządzić jako producent rozbudowanych kontrolek, ale dopiero raczkuje w obszarze ORM (a kosztuje tyle samo co LLBLGen, pomimo że się fajniej nazywa:) ). Poza tym nawet o kontrolkach można powiedzieć że działają bezawaryjnie, dopóki nie potrzebujemy zrobić czegoś ‘nietypowego’, a później zaczynają się strome schody. Z tego względu nawet nie przyglądałem się ich rozwiązaniu pomimo że zbiór featerów wymieniony na stronie jest dość fajny.
Ja bym nie byl tamik radykalem piszac: “DataSety (o których pisać nawet nie będę, bo traktowanie ich jako technologii dostępu do bazy danych w “normalnej aplikacji” to trochę naciągane rozumowanie)”. Wbrew pozorom DS moga byc naprawde wystarczajacym podejsciem do pewnych problemow. Moze i przyznanie sie do uzycia DS (napewno jednak nie zachwyt nad DS) jest faux pas i nie “trendi” w srodowisku “wyjadaczy .NET” ja jednak z checia przyznam sie ze uzylem 2 razy DS jako jakas forma dostepu do danych. ;-)
@Wojciech Gebczyk:
DS jako forma przechowywania wycinka danych w środowisku “occasionally connected” czy jak to nazwać – czemu nie? Też z nich korzystałem. Problem polega na tym, że łatwo jest nadużyć tego co nam oferują, ignorując dużo lepsze rozwiązania. “Faux pas” i “trendi” – może i prawda, ale jest to spowodowane promowaniem swego czasu przez Microsoft data setów jako jedynej słusznej drogi z aplikacji do bazy danych, co pokutuje do dziś. I wypuszczenie dwóch ORMów naraz niekoniecznie tą sytuajcę wyjasniło.
@Procent:
“Telerik z kolei może rządzić jako producent rozbudowanych kontrolek, ale dopiero raczkuje w obszarze ORM (a kosztuje tyle samo co LLBLGen, pomimo że się fajniej nazywa:) ).”
OpenAccess ORM jest rozwijany od 2004 r. (a wywodzi się z jeszcze starszego rozwiązania JDO Genie), najpierw pod szyldem Versant (jako Open Access .NET), później Vanatec (jako OpenAccess), a od zeszłego roku Telerik. Pomimo częstych zmian barw, nad jego rozwojem od samego początku pracuje ta sama ekipa z Niemiec.
Być może Telerik jest nowym graczem na rynku ORM, ale sam produkt miał sporo czas, żeby dorosnąć.
Ja za to zachecam do zwrocenia uwagi na Lightspeed firmy Mindscape:
http://www.mindscape.co.nz/products/lightspeed/default.aspx
@apl:
Dzięki za wyprostowanie mojego krzywego spojrzenia na ten temat.
@Grzech:
Nie słyszałem o tym, fajnie że pojawiają się linki do konkurencyjnych produktów.
Biedny ten kto pracuje w firmie, która nie pozwala na używanie produktów OpenSource. OR/Mów opensource jest sporo. Wystarczy zajrzeć tu:
http://csharp-source.net/open-source/persistence
Nie wiem czemu, ale czytając Twój post odniosłem wrażenie, że zaczynając projekt w LL… zaczynasz od bazy. Może się mylę. Ja wolę zaczynać od kodu, a baza jest pochodną tego co wymaga kod od miejsca składowania danych. :)
@dario-g:
Tak, w LLBLGen punktem wyjścia jest baza danych. Tak samo jest w większości ORMów – tylko NHibernate ze znanych mi rozwiązań pozwala na pójście w drugą stronę. (i wspomniany wyżej produkt Telerika, ale o tym dowiedzialem sie dzisiaj).
Nie oznacza to jednak, ze na samym poczatku tworzenia projekty trzeba zabierac sie za baze. Tak jak napisalem – tak czy siak wynik dzialania LLBLGen trzeba bedzie zmapowac na wlasne obiekty domenowe, wiec nic nie stoi na przeszkodzie stworzenia i zamodelowania ich najpierw. A dostep do danych i tak kryje sie ‘gdzies pod spodem’.
I translated it through google language tools as my Polish is a little rusty ;)
Thanks for the review of our work :). Yes it’s not Poco and the query API we have can be a little verbose at times, yet it’s so verbose because it’s a system which is compile time checked, and in times where linq wasn’t available, it was essential for us to have this. With our linq provider this should largely go away though.
We’re currently working on v3.0 which should arrive later this year (fall/winter 2009) and which will have (among a lot of other nice things) model-first ( so define entities, generate DDL SQL for database, also change sets!) and support for EF, nhibernate, our own runtime lib and linq to sql.
@Procent: “Tak, w LLBLGen punktem wyjścia jest baza danych. Tak samo jest w większości ORMów – tylko NHibernate ze znanych mi rozwiązań pozwala na pójście w drugą stronę.”
Do pewnego stopnia (tj. gdy już pogodzimy się z ograniczeniami narzuconymi na możliwość modelowania encji) umożliwia to również LINQ to SQL.
Mógłbyś napisać w czym jest lepszy od LINQ to SQL oprócz tego, że ten drugi jest ‘technologią umierającą’ ? Pozdrawiam.
@w:
Sam fakt, że Linq2Sql nie będzie rozwijany i wspierany przez Microsoft powinno wystarczyć.
Poza tym Linq2Sql z założenia NIE MIAŁ konkurować z NHibernate, Entity Framework czy LLBLGen. Oferuje on funkcjonalności WYMAGANE do kontaktu z bazą danych, i tyle; jest po prostu “mini-oer-mapperkiem”:).
Przykładem jednego obszaru jego “prostoty” może być chociażby ograniczona mozliwość odwzorowania dziedziczenia w bazie danych. O samym temacie można poczytać w artykule poświęconym EntityFramework z CodeMagazine (http://www.code-magazine.com/article.aspx?quickid=0712032&page=2, sekcja “Mapping Inheritance”). Linq2Sql wspiera tylko jedną “drogę”, czyli “Table per Hierarchy”.
Inny przykład: możliwość (oficjalnie) kontaktu jedynie z Sql Server.
Nie piszę że jest to zły produkt, bo nie jest. Jest po prostu uproszczony, ale to nie zmienia faktu że miał swoje zastosowanie w wielu scenariuszach. Dopóki nie zaczął być “martwy”…
To może ja podrzucę taki link:
http://damieng.com/blog/2009/06/01/linq-to-sql-changes-in-net-40
Ciężko na dobrą sprawę powiedzieć, co jest martwe, a co żywe w zakręconym świecie ORMów produkcji wujka M. Na chwilę obecną LINQ to SQL wygląda na bardziej żywy niż Windows Forms. (Inna sprawa, że nie jest to technologia nawet w ułamku tak dojrzała.)
Dzięki za odpowiedzi, mam nadzieje ze Linq jeszcze trochę pożyje, bo zdarzyłem go polubić. Pzdr.