











…far far away…
Bohaterami dzisiejszego spotkania są dwa współpracujące ze sobą twory (Bolki?), różniące się znacząco wiekiem. Partial classes (klasy częściowe…) zostały wprowadzone do .NET za czasów wersji 2.0 zarówno platformy .NET jak i języka C#. Partial methods z kolei to “najnowsza nowość”, bowiem przyjście na świat tej konstrukcji miało miejsce zaledwie kilka miesięcy temu, wraz z .NET 3.5, C# 3.0, LINQ, lamda, extensions itpm (i tym podobną magią). O ile jednak całe jej “rodzeństwo” w postaci wymienionych mechanizmów zostało należycie przedstawione developerskiemu światu, na ich cześć odbywały się imprezy i pokazy, o tyle o “metodach częściowych” słyszy się raczej niewiele. Usłyszmy więc teraz.
RU interested?
Odpowiedź na jakże szpanersko zadane pytanie wcale nie musi być jasna i oczywista. Zanim przejdę do meritum, nakreślę tło do mającej nastąpić za chwilę operacji na żywej tkance. A więc: co to są te tzw. “partiale”? Jedyny cel ich powstania to rozbicie JEDNEJ klasy na WIELE plików *.cs. Część klasy w Person.cs, reszta w Person.Part2.cs. Do czego to prowadzi? Nie owijając w bawełnę: do płaczu i zębów zgrzytania. Jeżeli klasa jest AŻ TAK rozbudowana, że musimy dzielić ją na kilka plików, to oznacza to tylko jedno: nakazujemy jej zajmować się zbyt wieloma rzeczami! Zrobiliśmy z niej wór na śmieci, złamaliśmy zasadę “high cohesion”, jesteśmy be i generalnie powinniśmy ją skasować i rozbić na wiele mniejszych. Klas, nie plików.
PO CO więc wprowadzono do .NET mechanizm tak jawnie promujący zły design, pozwalający na radosne tworzenie programistycznego błota? Zły, zły Microsoft? A no właśnie nie. Jest jeden scenariusz, gdy omawiane konstrukcje są, jakkolwiek to zabrzmi, “zbawcze”. Scenariusz ów to GENERACJA KODU. Dlaczego? Faktem oraz “oczywistą oczywistością” jest, że sens generowania kodu kończy się w momencie konieczności ręcznej jego edycji. Częściowe klasy i metody to miły sposób na ułatwienie sobie eliminacji tej czynności. Pozwólże zatem Czytelniku, że odpowiem za Ciebie na pytanie postawione tytule tego paragrafu. Jesteś zainteresowany bohaterami tego wpisu “wtedy i tylko wtedy”, gdy masz do czynienia z generacją kodu. Jeżeli nie masz – to zapomnij że istnieją i, na Mahometa, nie używaj ich w swoich projektach. Następne pokolenia programistów utrzymujących w przyszłości twój kod będą wdzięczne.
Partial classes
Na pierwszy ogień pójdą klasy, bowiem bez nich nie ma metod. (czy ktoś gdzieś za tak genialne stwierdzenia rozdaje nagrody?) Założenie jak i wykonanie jest banalne: w dwóch lub więcej plikach implementujemy klasę o tej samej nazwie. Jedyna różnica w stosunku do standardowego sposobu to dodanie słowa kluczowego ‘partial’ do modyfikatorów typu. Przykład praktycznego zastosowania tej sztuczki można zaobserwować chociażby tworząc najprostszy projekt Windows Forms w VS: wygenerowany kod odpowiedzialny za tworzenie kontrolek ląduje w Form1.designer.cs. Sami możemy zrobić coś takiego:
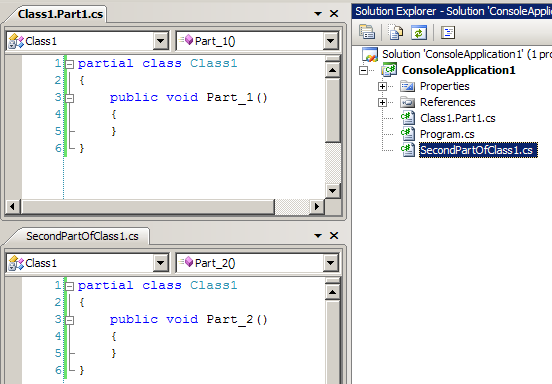
Jak widać – nazwy plików nie mają żadnego znaczenia. Kompilator C# zadba o to, aby wszystkie części zostały ze sobą odpowiednio sklejone. W dowód screen skompilowanego kodu – na tym etapie pojęcie “partial class” nie istnieje:
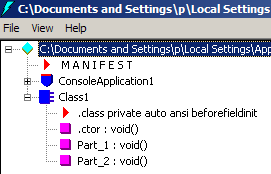
Co za tym idzie, obowiązują nas pewne ograniczenia. Nie można w kilku plikach zdefiniować sprzecznej hierarchii dziedziczenia, nie można jednej części oznaczyć jako ‘public’ a innej ‘internal’, nie można rozbijać części jednej klasy pomiędzy kilkoma projektami/modułami/bibliotekami. “I tak dalej…” Ale co z tego? Przecież przy generacji kodu żadne z tych ograniczeń w niczym nie przeszkadza. A resztą nie jesteśmy zainteresowani.
Gwoli ścisłości: wszystko co zostało napisane powyżej tyczy się nie tylko klas, ale także struktur i interfejsów.
Partial methods
Przechodzimy do niedopieszczonego dziecka ostatniej odsłony C#. Zaczniemy od przedstawienia: z czym to się je? Krótka demonstracja, z wykorzystaniem poprzedniego przykladu:
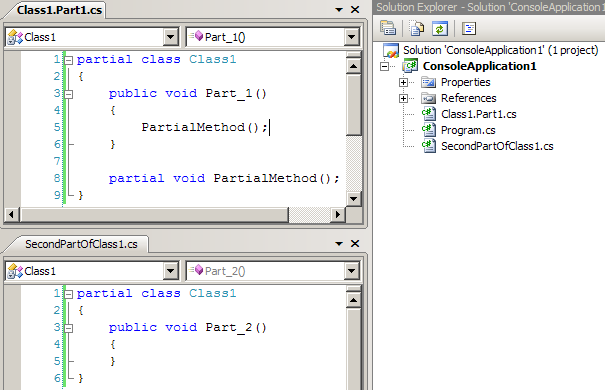
I co my tu mamy… Pierwsza część klasy definiuje częściową metodę o nazwie “PartialMethod” i wywołuje ją w swojej standardowej metodzie. Druga część bez zmian. Zerknijmy co otrzymaliśmy:
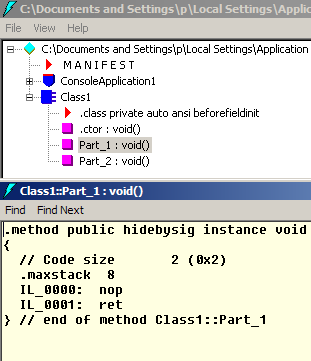
Hola hola! Kompilator zgubił metodę PartialMethod, zgubił też jej wywołanie! I tu jest właśnie magiczna csharpowa sztuczka: deklarujemy MOŻLIWOŚĆ zaimplementowania danej metody, na przykład w celu walidacji danych. Nie ma implementacji – nie ma wywołania. Kompilator wycina zarówno metodę jak i wszelkie odwołania do niej. Natomiast dopiero gdy w dowolnej części klasy zaimplementujemy CIAŁO metody – jest ona traktowana jak na metodę przystało.
Czy komuś zapaliła się w głowie żaróweczka z napisem “przecież takie cos już było!”? Bo było – identyczny efekt mogliśmy wcześniej osiągnąć deklarując prywatne zdarzenie. Ale: a) koncepcja zdarzeń przewiduje komunikację między klasami, a nie wewnątrz klas, b) ze zdarzeniami jest więcej roboty, c) zdarzenie jest odpalane zawsze, nawet gdy żaden subskrybent na nie nie oczekuje. Dzięki “partial methods” zyskujemy więc prostotę (piszemy metodę, nie musimy podpinać się pod zdarzenie) oraz (przy wielkich systemach może nawet zauważalną, albo przynajmniej mierzalną) korzyść wydajnościową.
Jakie ograniczenia czyhają na nas podczas zabawy z tym tworem? Pierwsze: metody takie są zawsze prywatne. Jest to jak najbardziej logiczne – przecież mogą one zostać usunięte podczas kompilacji, więc żaden inny kod nie powinien na nich polegać. Drugie: nie mogą zwracać żadnej wartości. Ponownie istnieje logiczne wytłumaczenie – nie możemy opierać logiki kodu na wartości zwracanej przez metodę, która podczas kompilacji ulec może brutalnej, absolutnej dezintegracji! Z tego samego powodu nie przekażemy też parametru z modyfikatorem out. Możemy natomiast do woli korzystać z dobrodziejstw słowa kluczowego ref, co pozwala na zasymulowane ominięcie tego ograniczenia:
1: partial void OnValidation(ref bool isValid); 2: 3: private bool Validate() 4: { 5: if (string.IsNullOrEmpty(this.Name)) 6: return false; 7: 8: //other standard generated validation 9: //... 10: 11: // was valid before partial method call 12: bool isValid = true; 13: 14: // give a chance for hand-written code to interfere with validation process 15: OnValidation(ref isValid); 16: 17: return isValid; 18: }
I po co to wszystko…?
Jeśli nie wszystko jest do końca jasne to kilka słów podsumowania. Krok pierwszy: generujemy kod oznaczony “partialami” tam gdzie to potrzebne. Krok drugi: dodajemy własne pliki rozszerzając wygenerowane klasy w razie konieczności. Czym może być owa konieczność? Na przykład dodatkowa metoda z jakąś “niskopoziomową logiką”. Albo charakterystyczna dla danej klasy właściwość zwracająca “wyliczone” dane: public string FullName { get { return this.FirstName + ” ” + this.LastName; } }. Znajome? Lub partial method walidujące zmienianą właściwość, generowana i wołana tylko wtedy gdy faktycznie zaimplementujemy jej ciało. I… koniec. Lądujemy z jedną klasą zawierającą wszystkie niezbędne funkcjonalności. Podobny efekt można oczywiście było osiągnąć i wcześniej – np przy pomocy dziedziczenia z wygenerowanych klas (bądź w drugą stronę). Wprowadzało to jednak dodatkowy (najczęściej zbędny) poziom w hierarchii, którego teraz z powodzeniem możemy się pozbyć.
I na koniec: należy zdawać sobie sprawę z tego, że nie jest to rozwiązanie nadające się do KAŻDEGO projektu. Warto jednak wiedzieć, że taki mechanizm istnieje, i przynamniej rozważyć jego wykorzystanie. Praktyczny przykład można przeanalizować m.in. przeglądając kod wygenerowany przez designer LINQ To SQL.
I na koniec końców: czuję się w obowiązku podreślić jeszcze raz, że nie potrafię znaleźć dla omawianych konstrukcji zastosowania innego niż pomoc w generowaniu kodu i nie zalecam ich stosowania w innych scenariuszach. Proszę mnie uświadomić jeśli mam na oczach ciemne klapy i nie widzę czegoś oczywistego.
Teraz to już naprawdę na koniec, mały tip: generując kod i zlepiając go w jedną klasę warto podkreślić “wzajemną przynależność” spokrewnionych plików i zgrupować je w Visual Studio. [autoreklama]Na przykład tak, jak opisałem to w poście “Zwijanie plików w Visual Studio”.[/autoreklama]
Let the party begin!
